

在了解了细粒度代码分割方案的优点后,下面我们将以老朋友前端优化示例项目为例,来完整演示增加细粒度代码分割的流程和具体代码改动。
4. 示例:为前端项目增加细粒度代码分割#
1. 确认优化前状态#
优化开始前,我们先通过webpack-bundle-analyzer插件,确认前端工程项目当前的编译打包产物的状况,例如下图就是配套示例项目fe-optimization-demo 在模块懒加载优化后的分析图:

可以看到,vendors.${hash}.js包含了许多模块,体积非常大。
每次编译打包,vendors区块中任何一个模块变化,都会导致vendors区块的产物文件名称中的哈希字符串更新。进而导致生产环境用户需要重新下载vendors.${hash}.js,使缓存命中率降低。
细粒度代码分割正是为了解决上述痛点而发明的。
2. 增加细粒度代码分割缓存组#
具体做法是,在Webpack配置中增加lib,shared2个缓存组(cacheGroup),将vendors这样体积较大的模块进一步合理、精细地分割。
具体的改动主要有3步:
- 删除原有的
vendors缓存组:释放其包含的模块。 - 禁用默认缓存组:避免干扰细粒度代码分割。
- 新增
lib,shared2个缓存组配置
《细粒度代码分割》完整改造代码示例MR:https://github.com/JuniorTour/fe-optimization-demo/pull/3
const crypto = require('crypto');
const path = require('path');
const MAX_REQUEST_NUM = 20;
// 指定一个 module 可以被拆分为独立 区块(chunk) 的最小源码体积(单位:byte)
const MIN_LIB_CHUNK_SIZE = 10 * 1000;
const isModuleCSS = (module) => {
return (
// mini-css-extract-plugin
module.type === `css/mini-extract` ||
// extract-css-chunks-webpack-plugin (old)
module.type === `css/extract-chunks` ||
// extract-css-chunks-webpack-plugin (new)
module.type === `css/extract-css-chunks`
);
};
module.exports = {
optimization: {
// https://webpack.js.org/configuration/optimization/#optimizationruntimechunk
// 指定是否将Webpack的运行时(每个文件中重复的、用于加载的函数)拆分为独立文件,能减少重复代码。
runtimeChunk: 'single',
splitChunks: {
maxInitialRequests: MAX_REQUEST_NUM,
maxAsyncRequests: MAX_REQUEST_NUM,
minSize: MIN_LIB_CHUNK_SIZE,
cacheGroups: {
defaultVendors: false,
default: false,
lib: {
chunks: 'all',
test(module) {
return (
module.size() > MIN_LIB_CHUNK_SIZE &&
/node_modules[/\]/.test(module.identifier())
);
},
name(module) {
const hash = crypto.createHash('sha1');
if (isModuleCSS(module)) {
module.updateHash(hash);
} else {
if (!module.libIdent) {
throw new Error(
`Encountered unknown module type: ${module.type}. Please check webpack/prod.client.config.js.`,
);
}
hash.update(
module.libIdent({ context: path.join(__dirname, '../') }),
);
}
return `lib.${hash.digest('hex').substring(0, 8)}`;
},
priority: 3,
minChunks: 1,
reuseExistingChunk: true,
},
shared: {
chunks: 'all',
name(module, chunks) {
return `shared.${crypto
.createHash('sha1')
.update(
chunks.reduce((acc, chunk) => {
return acc + chunk.name;
}, ''),
)
.digest('hex')
.substring(0, 8)}${isModuleCSS(module) ? '.CSS' : ''}`;
},
priority: 1,
minChunks: 2,
reuseExistingChunk: true,
},
},
},
},
};这份配置中,值得注意的细节是:
限制了最大产物文件数量:声明了
maxInitialRequests: MAX_REQUEST_NUM, maxAsyncRequests: MAX_REQUEST_NUM,避免数量过多,超过HTTP/2协议的并发数量,导致页面资源加载阻塞,用户体验受损,通常建议不要超过20。指定了
minSize,避免拆分出的模块体积太小,缓存优化效果不明显。2个缓存组的
name都包含基于内容的哈希值,类似Webpack自带的contentHash。同时也有通过模块内容,拆分模块的作用。lib的优先级(priority)要比shared高,目的是为了优先拆分出独立性较强的模块。
3. 确认分割效果#
完成上述配置后,即可再次编译打包,通过bundle-analyzer-plugin确认分割后的模块:
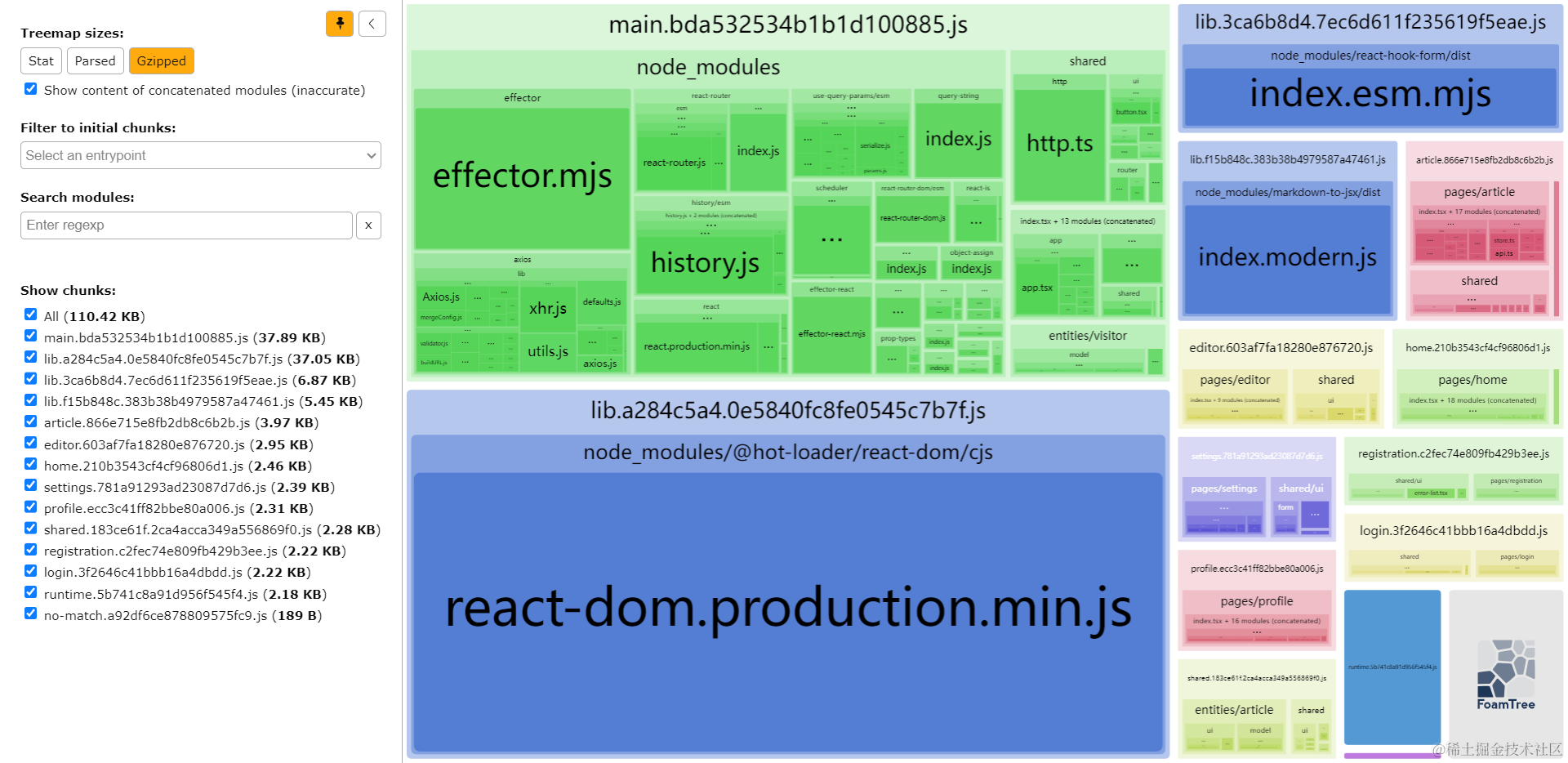
从上图中,我们可以看到显著的变化:
- 多个模块被拆分为了独立的
lib.${hash}.js,例如@hot-loader/react-dom、react-hook-form、markdown-to-jsx。 - 产生了一个
shared.${hash}.js,包含了article-preview.tsx、shared/row.tsx等模块,自动把多个组件间共用的模块进行了分割处理。

这些新增的产物文件,独立性较强,代码更新后,多次打包构建,仍然能保持文件名中的哈希不变,部署到生产环境后,能长期复用本地缓存,缓存命中率更高。
这样的变化完美地解决了我们之前提到的痛点:
- 配置复杂,开发体验不佳:这套配置普适性极强,不必改造即可适用于大多数前端项目,避免了复杂配置影响开发体验。
- 配置方案健壮性不强,可维护性不好:这套配置能适应项目的快速迭代变化,长时间不需要调整,仍然能保持较好的分割效果、缓存命中率,可维护性极佳;
- 用户体验不好:缓存命中率更高,相应的使页面加载渲染更快,用户体验更好。
开发体验好、健壮性强、用户体验好正是这套细粒度代码分割方案的优势所在。
4. 健壮性证明:共用(shared)模块示例#
为了进一步演示细粒度代码分割的优点,我们再主动增加一个多组件共用模块,来看看这套分割方案是否需要手动调整,会如何应对。
我们以近年来因体积庞大(源码700+KB)而在前端界臭名昭著的moment.js库为例,将其引入我们的项目中,并在2个组件间复用:
《添加moment.js作为共用(shared)模块示例》完整代码示例:https://github.com/JuniorTour/fe-optimization-demo/pull/3/commits/050a34943d0955fc016d71f4a945715eee572fdd
// src\shared\temp-shared-chunk-example.ts
import moment from 'moment';
export function getTime() {
return moment().format('MMMM Do YYYY, h:mm:ss a');
}
// 导入模块 1. src\pages\home\index.tsx
import { getTime } from '@/shared/temp-shared-chunk-example';
getTime();
// 导入模块 2. src\pages\login\index.tsx
import { getTime } from '@/shared/temp-shared-chunk-example';
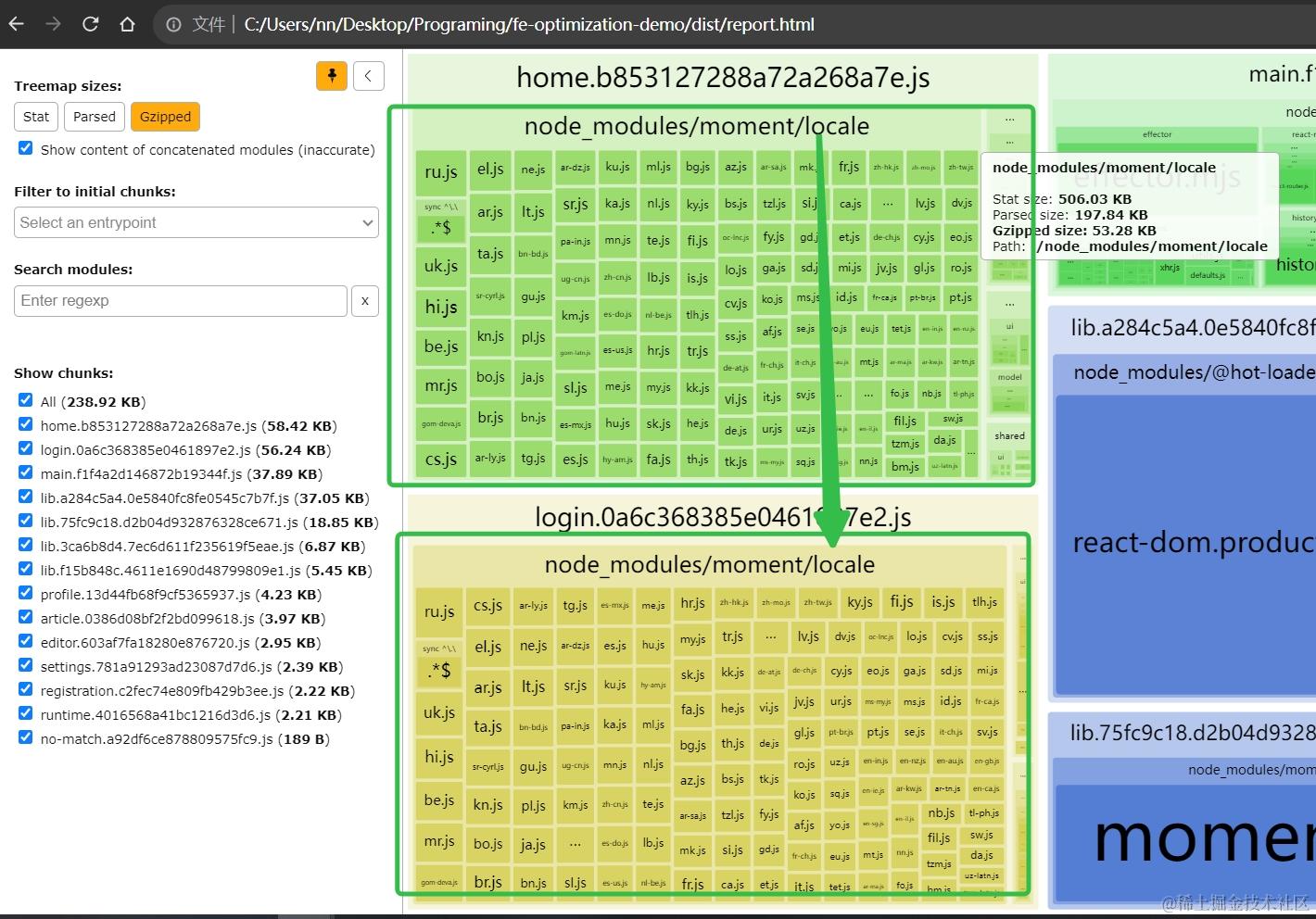
getTime();代码修改完成后,再次运行bundle-analyzer-plugin,确认状况,可见下图:

可以看到,moment.js新引入的代码被自动拆分成了2个产物文件,各自有独立的带哈希文件名,只要moment.js版本号不更新,生产环境的缓存就可以一直复用,缓存效率极高。
这也进一步证明了这套细粒度代码分割方案的健壮性。
注:
shared和lib缓存组的辨析:共性:shared缓存组和lib缓存组的目标都是通过细粒度地分割代码模块,提高缓存的命中率,优化用户体验。
特性:shared缓存组的特有目标是将多个区块间共用的代码进行拆分,避免模块被重复打包进多个区块。
此外,shared缓存组优先级是
priority: 1,比lib缓存组要低。示例图-无shared,只有lib,导致
moment/local模块被重复打包:
5. 获取全部产物清单#
细粒度代码分割后的产物数量较多,如果需要完整清单,可以使用webpack-manifest-plugin随编译打包生成一份JSON格式的产物清单文件,用于服务端渲染时加载、生产环境部署。
请看代码示例:
《以使用
webpack-manifest-plugin生成产物清单》完整代码示例:https://github.com/JuniorTour/fe-optimization-demo/pull/3/commits/788bbd580455295a4541b608db8eee6c015796f2
// webpack\production.config.js
const { WebpackManifestPlugin } = require('webpack-manifest-plugin');
const PUBLIC_PATH = 'http://localhost:3000/';
module.exports = {
mode: 'production',
// ...
plugins: [
new WebpackManifestPlugin({
fileName: 'assets-manifest.json',
generate: (seed, files) => {
const entrypoints = new Set();
files.forEach((file) => {
const chunkGroups = file?.chunk?._groups;
if (chunkGroups) {
chunkGroups.forEach((group) => entrypoints.add(group));
}
});
const entries = [...entrypoints];
const entryArrayManifest = entries.reduce((acc, entry) => {
const name = entry?.options.name || entry?.runtimeChunk.name;
const chunks =
entry?.chunks?.map((chunk) =>
chunk.files.map((file) => PUBLIC_PATH + file),
) || [];
const allFiles = [].concat(...chunks).filter(Boolean);
return name ? { ...acc, [name]: allFiles } : acc;
}, seed);
return entryArrayManifest;
},
}),
],
}这段代码中,我们利用WebpackManifestPlugin获取Webpack打包的产物数据(files),遍历每个产物文件,找到其对应的区块(chunk),将属于相同区块的文件拼接起来,作为清单文件的内容。
运行编译打包后,就会在dist目录中额外生成一个名为assets-manifest.json的文件,其内容就是每个区块加载所需的静态资源文件,并且因为我们已经做了路由懒加载优化,所以这里生成的就是前端路由对应的产物文件,例如:
{
"main": [
"http://localhost:3000/runtime.8d50d2f1d0dbd9f95dd0.js",
"http://localhost:3000/lib.a284c5a4.0e5840fc8fe0545c7b7f.js",
"http://localhost:3000/main.030bb00c221b2a80e00e.css",
"http://localhost:3000/main.f6360d0de4d842c6d6bc.js"
],
"login": [
"http://localhost:3000/lib.75fc9c18.d2b04d932876328ce671.js",
"http://localhost:3000/shared.cc020c28.91c44f0c97414e03e3ae.js",
"http://localhost:3000/login.18c40a63634cb8fc0422.css",
"http://localhost:3000/login.2dd91b1f4cd8a0beecaa.js"
],
"profile": [
"http://localhost:3000/shared.183ce61f.1c528f06dcefa66a9d45.js",
"http://localhost:3000/profile.16c4eba5c2e58679bc5b.css",
"http://localhost:3000/profile.d4bf82924e65660a99b7.js"
],
"article": [
"http://localhost:3000/lib.3ca6b8d4.7ec6d611f235619f5eae.js",
"http://localhost:3000/article.9803c033314d2ed0ca8e.css",
"http://localhost:3000/article.0386d08bf2f2bd099618.js"
],
"markdown-to-jsx": [
"http://localhost:3000/lib.f15b848c.4611e1690d48799809e1.js"
]
}5. 验证,量化与评估#
1. 验证#
1. CDN需要使用HTTP/2版本#
注意!
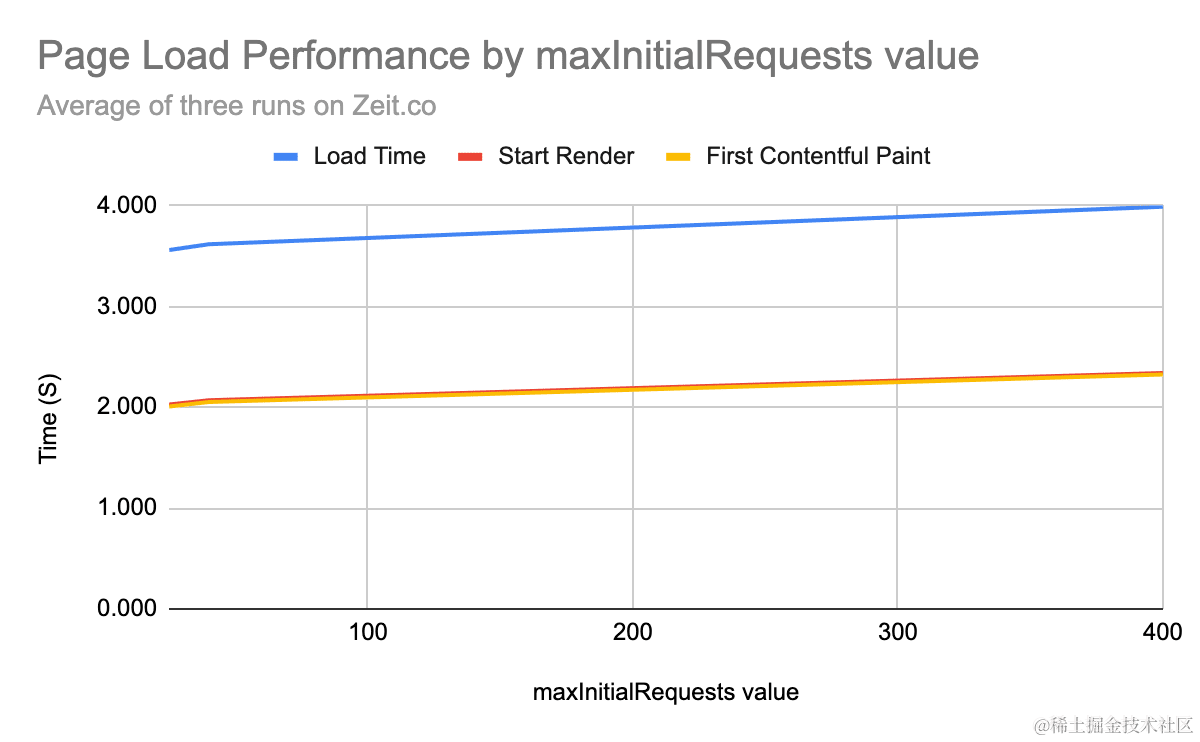
细粒度代码分割往往会产生20个以上的产物文件,需配合HTTP/2协议的多路复用特性,对多个产物文件复用同一TCP连接,才能避免同时下载文件过多,阻塞页面加载渲染。
所以上线前务必为CDN开启HTTP/2协议,详细介绍请参考上文第5节《CDN最佳实践》
注:HTTP协议同时链接数量限制
HTTP/1.1 及之前的HTTP版本,对单个域名只能建立不超过6个TCP链接,所以如果一次性加载6个以上的资源,会导致资源排队阻塞。
但是基于HTTP/2协议,根据Chrome官方的测算,初始请求资源数小于100个,对用户体验的负面影响都微乎其微。
所以使用基于HTTP/2协议的CDN,就可以放心大胆地使用细粒度代码分割了。
2. 基于webpack-bundle-analyzer分析产物文件组成模块#
打包相关的优化,分析验证产物文件组成模块都是必不可少的环节。
推荐做法是用webpack-bundle-analyzer分别在优化前、后生成一份报告HTML文件,保存下来,并相互对比。
分析验证的要点是:
lib类型的产物文件有哪些,是否都是长期不变、内容稳定的模块,体积大小如何。shared类型的产物文件,被哪些区块共用,是否符合预期。- 有没有遗留下体积较大的模块,期望被分割为独立文件,但最终没有被拆分。
- 项目总体积、各文件体积的变化。
3. CSS分割后的样式覆盖问题#
代码分割后,有时会出现CSS文件数量变多、CSS样式覆盖错乱的问题。
例如:
// 1. 代码分割优化前
<link href="/main.css" rel="stylesheet" type="text/css" />
<button class="btn confirm-btn">Confirm</button> // 最终前景色为红色(red)
// main.css
.btn {
color: blue;
}
// main.css
.confirm-btn {
color: red;
}
// 2. 代码分割优化后
<link href="/main.css" rel="stylesheet" type="text/css" />
<link href="/btn.css" rel="stylesheet" type="text/css" />
<button class="btn confirm-btn">Confirm</button> // 最终前景色为蓝色(blue)
// btn.css
.btn {
color: blue;
}
// main.css
.confirm-btn {
color: red;
}上述示例中,class为"btn confirm-btn"的button元素,在代码分割优化前,前景色为红色。而代码分割后,产物文件多了一个btn.css,加载后的颜色,就会变成蓝色。
原因是:代码分割也会分割CSS模块,分割后多了一个btn.css,加载顺序后于mian.css。会因为同样优先级(specifity)的CSS 选择符,后声明的覆盖先声明的规则,这条CSS的隐式特性,导致.confirm-btn被.btn覆盖,样式随之变化。
解决方案可以考虑:
- 手动增加
class优先级,例如把.confirm-btn {}改成div.confirm-btn {},多一级选择符,从而实现样式覆盖,规避CSS加载顺序文件。但是如果样式错乱的元素较多,定位、修改会非常麻烦,这个解决方案不太实用。 - 使用CSS in JS方案,规避CSS“后声明规则覆盖先声明规则”的隐式特性。详情请见后文的第13小节《用CSS in JS 解决CSS痛点》
- 增加一个缓存组,将所有CSS都合并为一个文件,避免先后加载导致样式错乱,例如Gatsby 框架源码中的styles缓存组:
styles: {
test(module) {
return isCssModule(module)
},
name: `styles`,
priority: 40,
enforce: true,
},4. 各路由加载资源体积变化#
代码分割优化效果,可以通过对比各路由加载资源体积变化,在本地开发环境初步确认。
通常来说,细粒度代码分割不会对产物总体积有显著影响,其主要优化目标是提高多次部署更新后的缓存命中率。
2. 建立量化指标#
1. JS资源缓存命中率指标#
细粒度代码分割会直接影响JS加载是否命中了浏览器的本地缓存,我们可以继续复用懒加载中建立的缓存命中率指标,并通过上报资源的类型过滤出JS类型的缓存命中率。
例如:
const resourceTypes = {
document: 'Document',
script: 'Script',
link: 'Link',
stylesheet: 'Stylesheet',
img: 'Image',
media: 'Media',
font: 'Font',
xhr: 'XHR',
fetch: 'Fetch',
other: 'Other',
};
function checkResourceCacheHit() {
// ...
const perfEntries = performance.getEntriesByType('resource');
for (const entry of perfEntries) {
// ...
let hitCache = entry.duration < 50;
// 新增 type 变量
const type =
resourceTypes[resource.initiatorType] || resourceTypes['other'];
report(
'cacheHiteRate',
{
hitCache,
name: entry.name,
type, // 作为新增的 label 上报到 Grafana
},
'缓存命中率计数指标'
);
}
}在上述代码中,我们新增了type变量,取自PerformanceResourceTiming的initiatorType资源类型字段,作为新增的label上报到 Grafana。
同时在Grafana中进行可视化图表数据查询时,增加label作为查询参数即可筛选出我们想要关注的JS类型资源,查询语句示例:cacheHiteRate{hitCache="true", type="Script"}。
2. FCP 和LCP#
细粒度代码分割提高静态资源的缓存命中率后,预计可以减少页面加载、解析资源的体积,加快页面渲染,从而优化FCP和LCP用户体验指标的状况。
所以继续复用基于web-vitals库建立的FCP和LCP指标,也可以量化优化效果。
3. 评估优化效果#
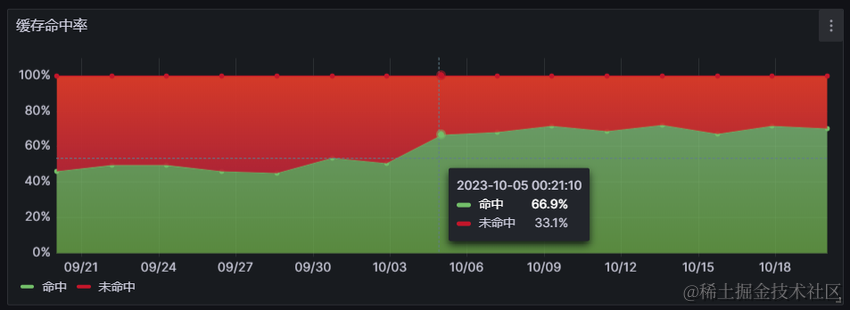
如果FCP和LCP指标评分为优的样本占比或是缓存命中率指标,在优化后,有所提高,并且保持长期稳定,那就说明我们的细粒度代码分割产生了优化效果,改善了用户体验。
- 例如下图中的缓存命中率指标在10-04优化上线后,有了显著的提高:
对于加载静态资源总体积指标,只要确认加载的静态资源体积没有1%以上的大幅异常增加,即可说明优化没有产生负面影响,例如下表是fe-optimization-demo 应用细粒度代码分割后,各路由的体积变化:
| 加载JS体积(单位:KB) | 优化前(仅懒加载) | 优化后(懒加载 && 细粒度代码分割) | 差异 |
|---|---|---|---|
| 首页(/home ) | 85.0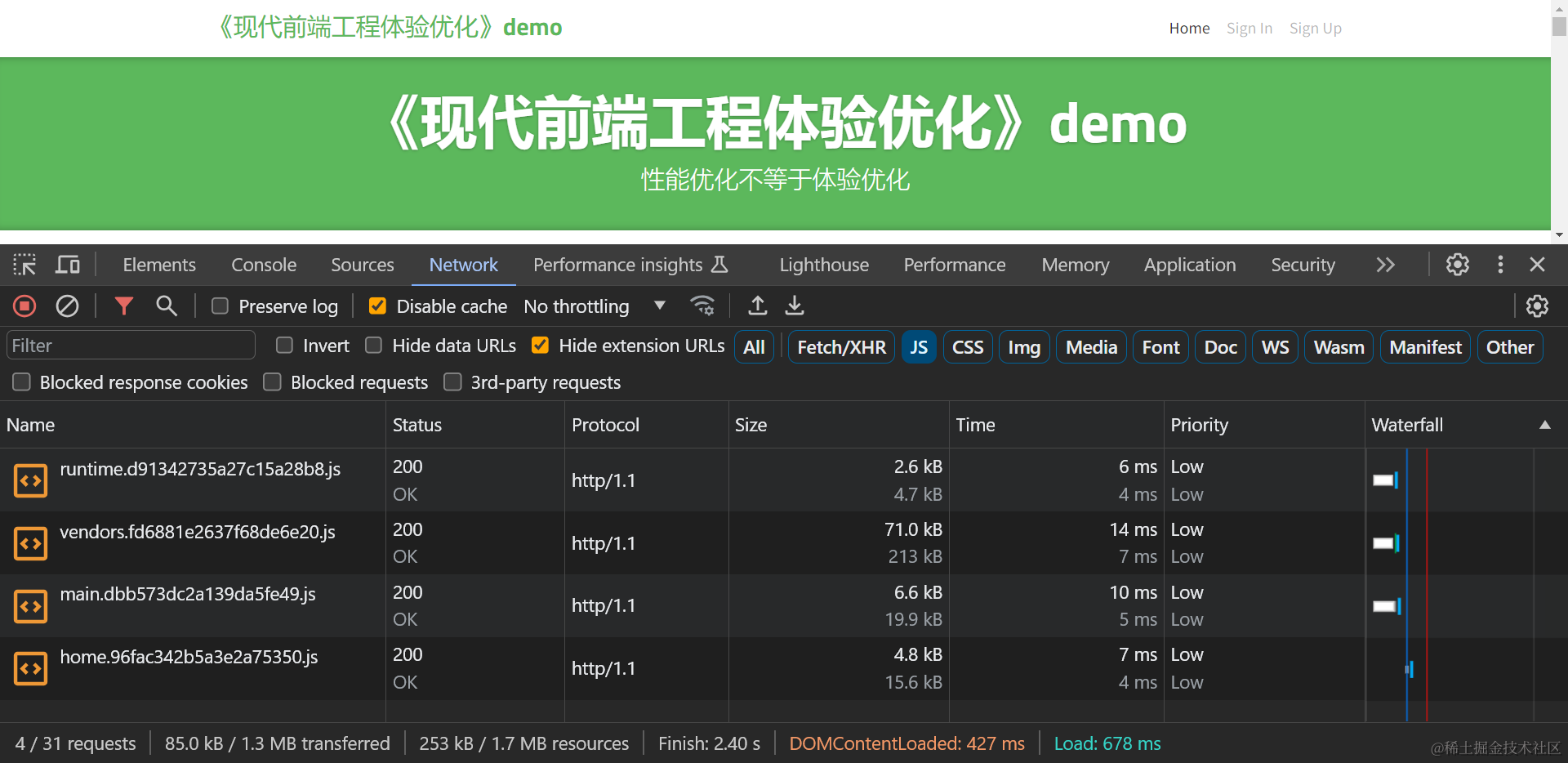 | 86.0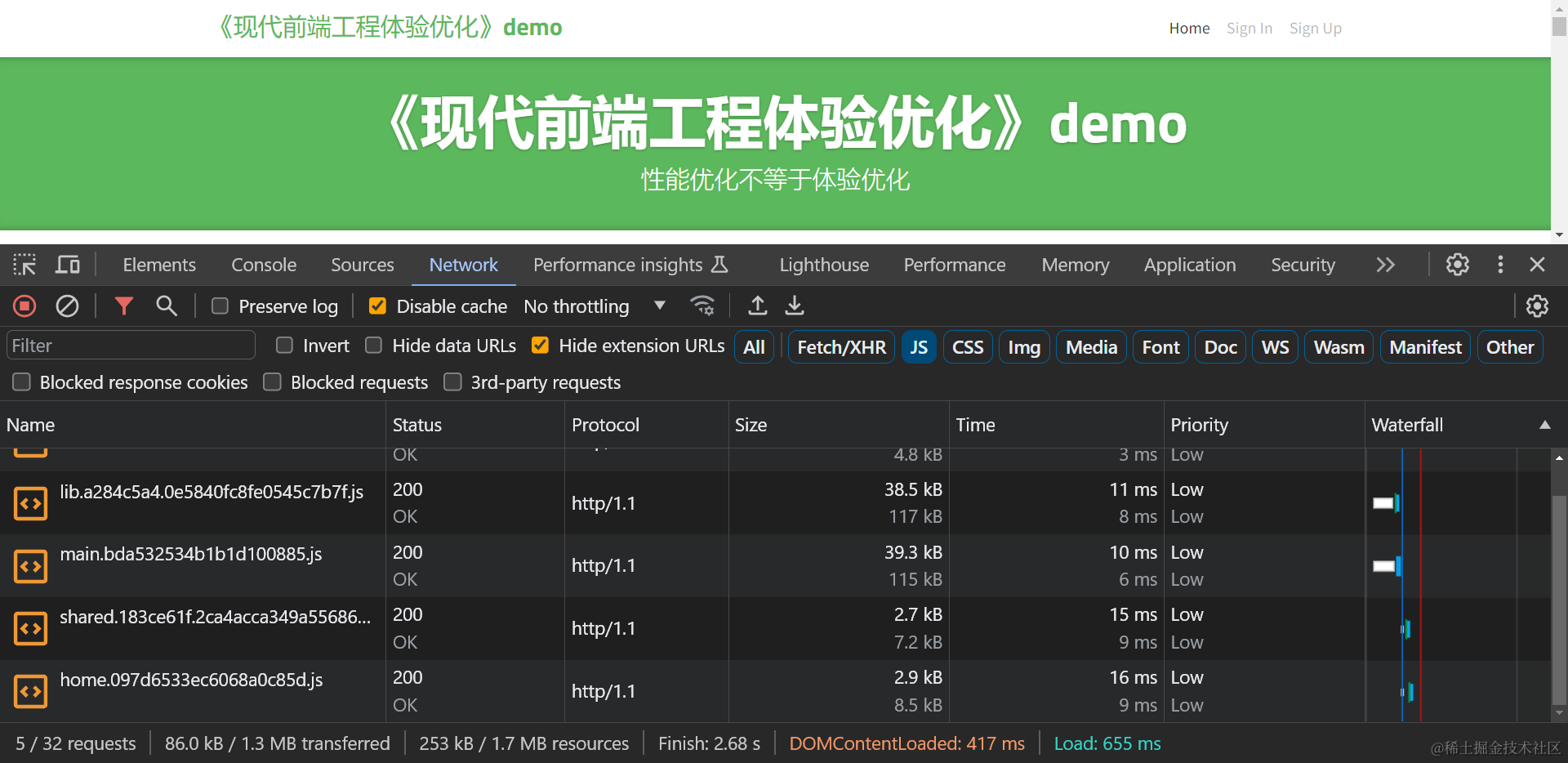 | +1 KB (+1% ) |
| 文章页(/article)加载JS体积 | 98.1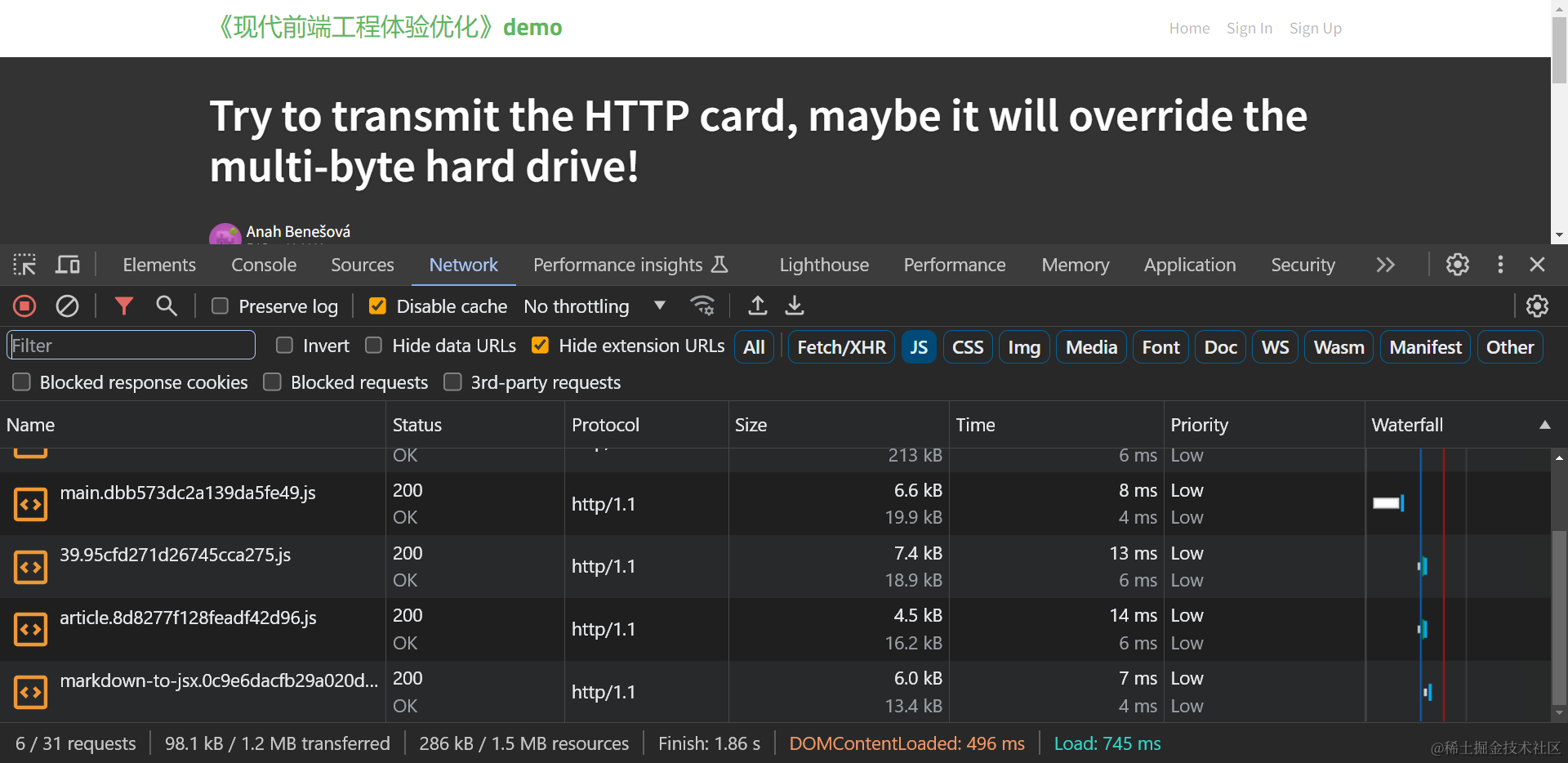 | 98.3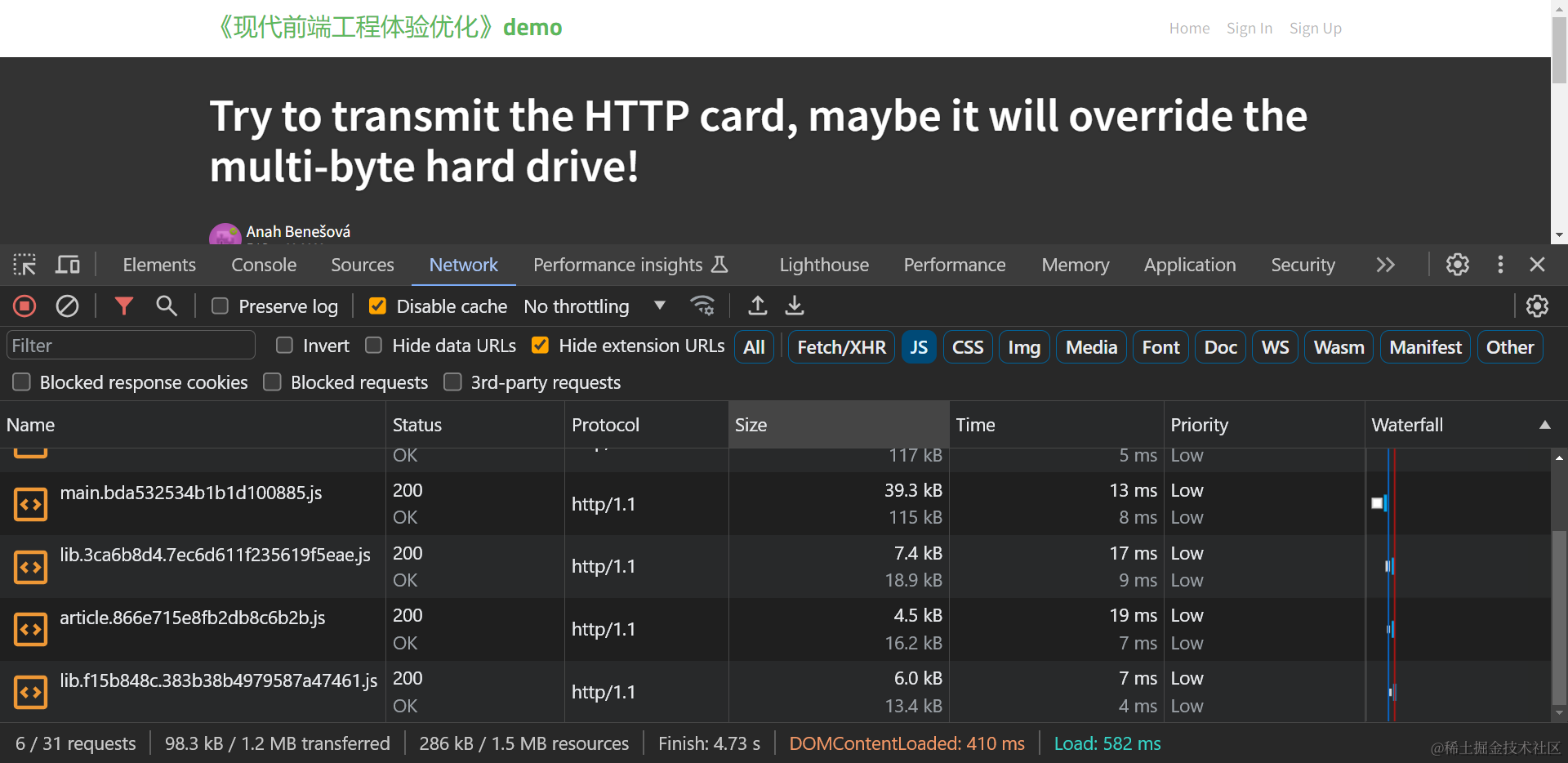 | +0.2 KB(+0.2%) |
| 登录页(/signin)加载JS体积 | 82.8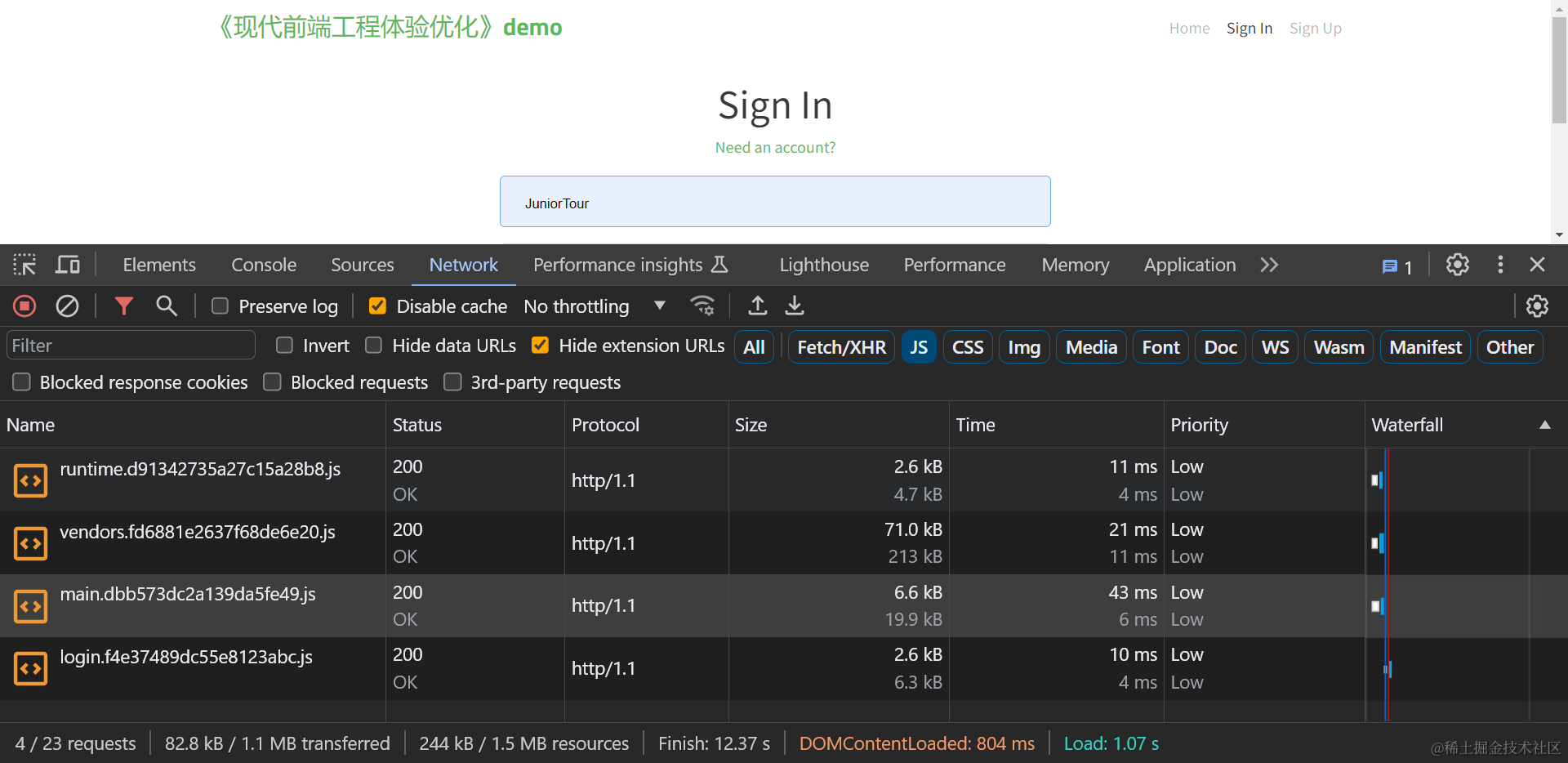 | 83.0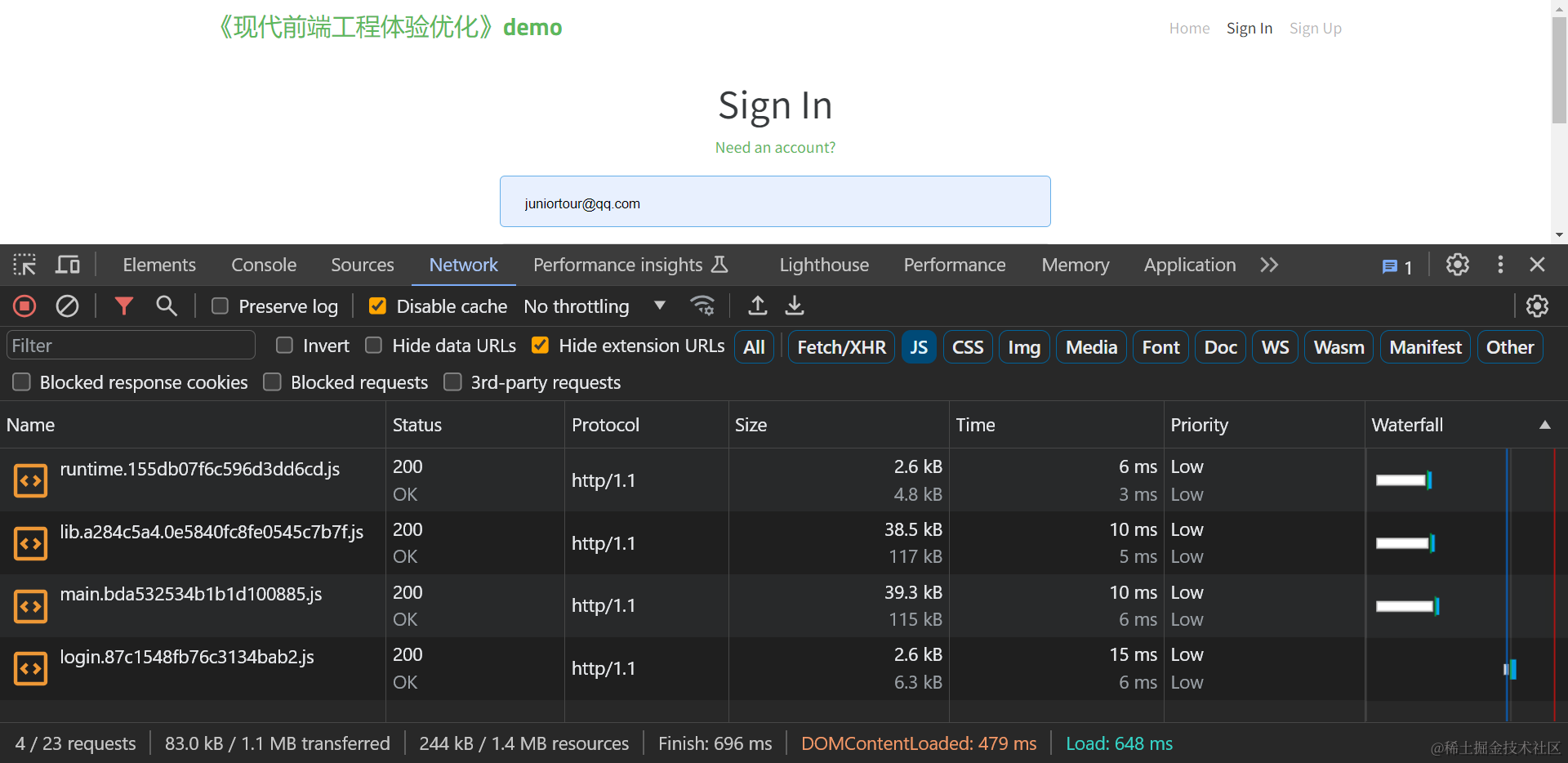 | +1 KB (+1% ) |
虽然让前端应用加载静态资源的体积增加了1%,但因为幅度较小,所以不必过于关注。
这点变化,相较于缓存命中率指标的改善和FCP,LCP的优化,几乎可以忽略不计。
小结#
在这2节《代码分割最佳实践:细粒度代码分割》中,我们首先一起学习了Webpack的代码分割原理和12项核心配置逻辑。
接下来,又针对传统代码分割的痛点,介绍了更加先进、体验更好的细粒度代码分割方案。
同时以fe-optimization-demo项目为例演示了实施优化的具体过程和潜在问题,验证了这一优化方案的健壮性和优化效果。