

有了获取用户体验数据的工具web-vitals,许多人会直接在本地开发环境或内部测试环境获取用户体验指标数据,用于评估优化效果,但是这样的做法有显著的问题:
- 样本总量较少:开发测试环境的用户数量较为有限,往往只有个别内部同事访问,收集到的数据量较少,数据的波动也会很大。
- 数据不具有广泛代表性:只在内部环境收集
web-vitals数据,忽略了生产环境中真实用户千差万别的网络状况、软硬件性能,这样的数据不能代表真正的用户体验。
所以,只在开发测试环境使用web-vitals收集用户体验指标数据是远远不够的,我们需要到广阔无垠的生产环境中收集最广大用户的真实数据,以便准确了解现状、确定优化目标、评估优化效果。
笔者在此推荐一套经过实践检验、开发体验较好的生产环境数据采集工具:Prometheus 和 Grafana。
1. Prometheus 及 Grafana 简介#
Prometheus 是一款开源的数据监控解决方案,主要包括以下模块:
- 面向各种编程语言的数据采集SDK(例如面向 Node.js 的NPM包客户端:prom-client)
- 接收数据上报的服务器后端应用
- 基于时间序的数据库
- 基础的数据可视化前端应用
具有强大的拓展能力,可以方便快速地融合进已有的项目中,作为数据监控中台的工具使用。
Grafana 是一款开源的数据可视化工具,主要有以下特性:
- 兼容 Prometheus 在内各种数据库的数据查询工具
- 内置海量可视化图表模板的前端应用
- 支持免费的私有化部署
将 Prometheus 与 Grafana 整合进我们的项目中就能实现强大的数据收集、可视化能力。
下面我们以Node.js为例,演示如何接入这2款工具。
2. 接入演示#
我们将基于:
- Grafana 官方的云端应用
- 本地环境自建的 Node.js 服务器应用
- Node.js 的 Prometheus 数据收集SDK:
prom-client
演示如何从本地环境收集web-vitals数据,上传到 Grafana,最终创建出数据可视化图表。
首先,我们注册并登录 Grafana 官方的云端应用:https://grafana.com/get/ ,每个账户都有永久免费的试用额度供我们体验。
完成注册后,我们就会进入 Grafana 的看板页面,这里是我们管理数据可视化图表、接入数据源的主要工作区域。
但因为此时我们还没有接入数据,所以内容还是一片空白。
注:对于Grafana来说,不同的数据源有不同的特性,例如:
- 查询语句的语法
- 是否支持日志全文查询
Grafana 支持众多数据源,如果下文介绍的 Prometheus 不适合你的前后端架构,可以参考官方文档选择
Elasticsearch、Graphite等其他数据源:https://grafana.com/docs/grafana/latest/datasources/如果只需要指标收集和存储,建议选择 Prometheus 或 Graphite;
如果需要结合服务端日志进行分析,对日志中包含的数据做可视化,建议选择 Elasticsearch;
接下来我们需要启动一个基于prom-client的 Node.js 服务器作为我们的数据收集应用。
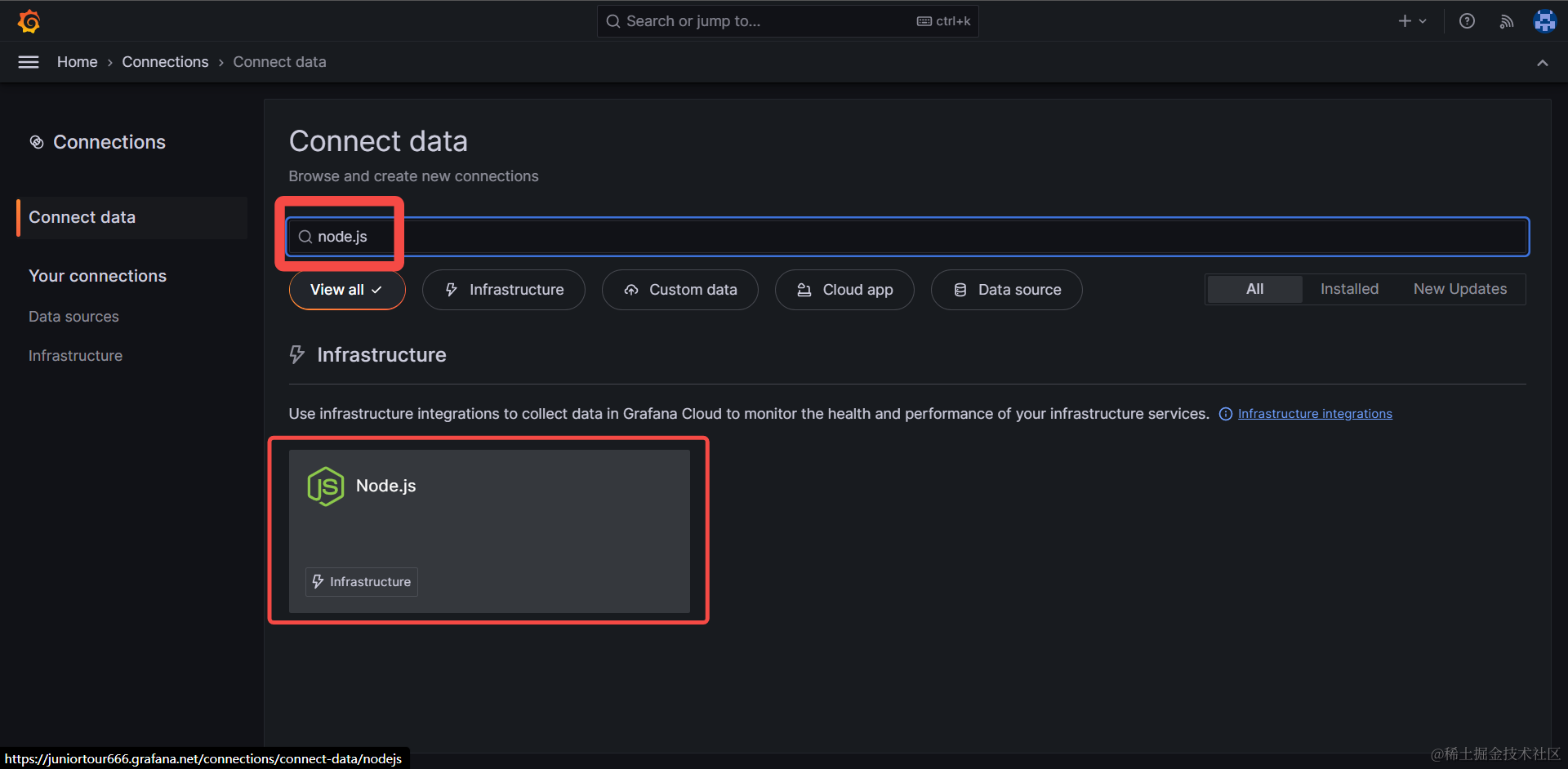
首先我们从左侧侧边栏访问 Connection > Connect data 目录,搜索 node.js 即可找到官方推荐的 Node.js 应用接入基础设施:
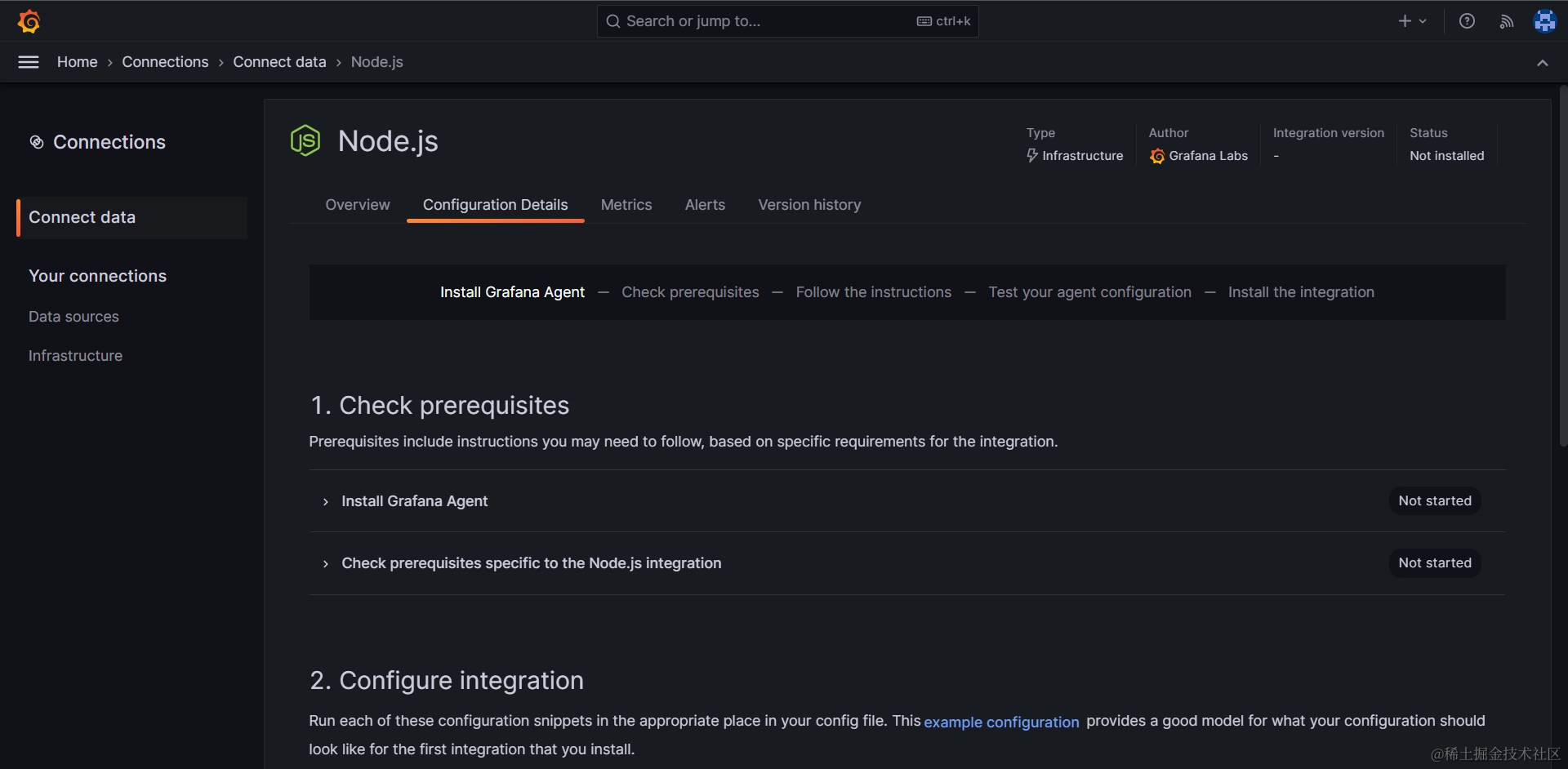
1. 安装配置Grafana Agent#
点击进入 Node.js Infrastructure 后,我们的目标是按照页面上详细的分步骤指引,安装Grafana Agent用于收集、转发本地的Prometheus数据。
首先,我们点击第一步的Run the Grafana agent按钮,在弹窗中选择安装目标对应的系统和CPU架构: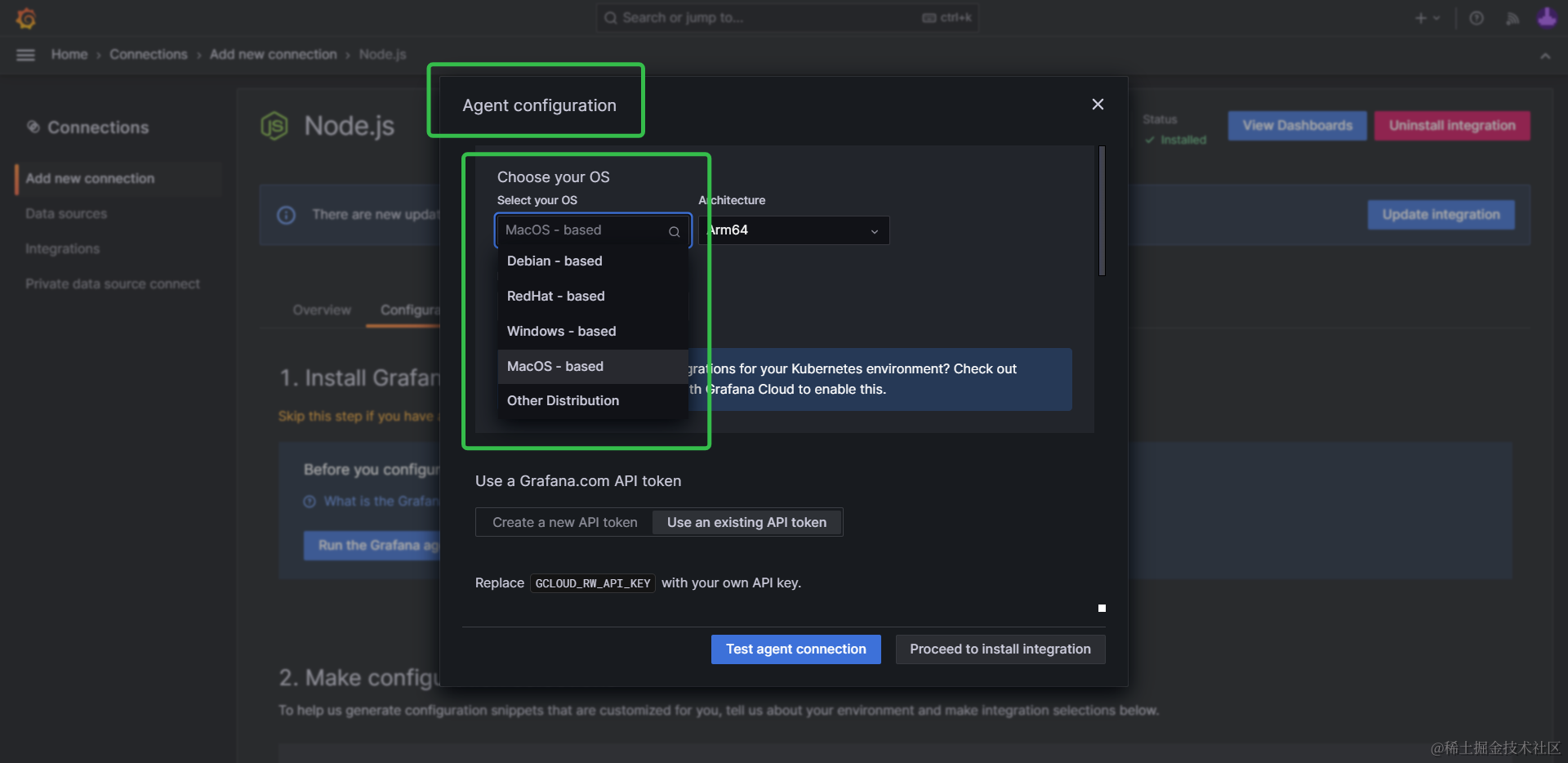
接下来,输入 API key 的备注名,点击 Generate API token 生成令牌,随后会提示生成已完成:Your API token has been generated below.,这段token将会自动添加到后续的安装脚本中,用于验证身份。
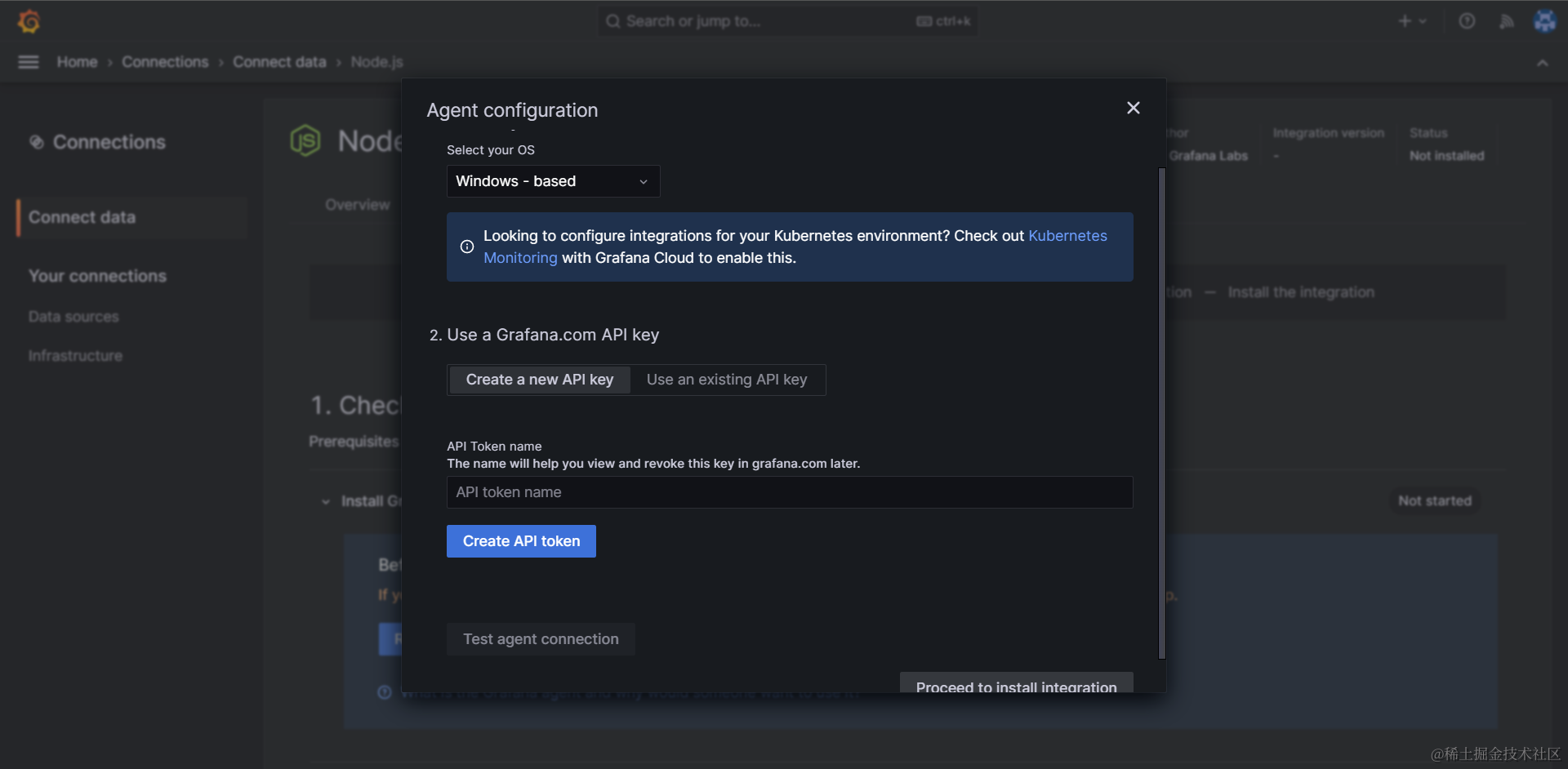
最后,我们复制并运行弹窗中生成的安装脚本命令行(Run this command to generate the config file后的内容),下载、安装 Grafana Agent 应用到本地,用于转发本地收集的数据到远端 Grafana 服务器,这个应用的下载和安装可能需要一定时间(建议搭配全局科学上网):
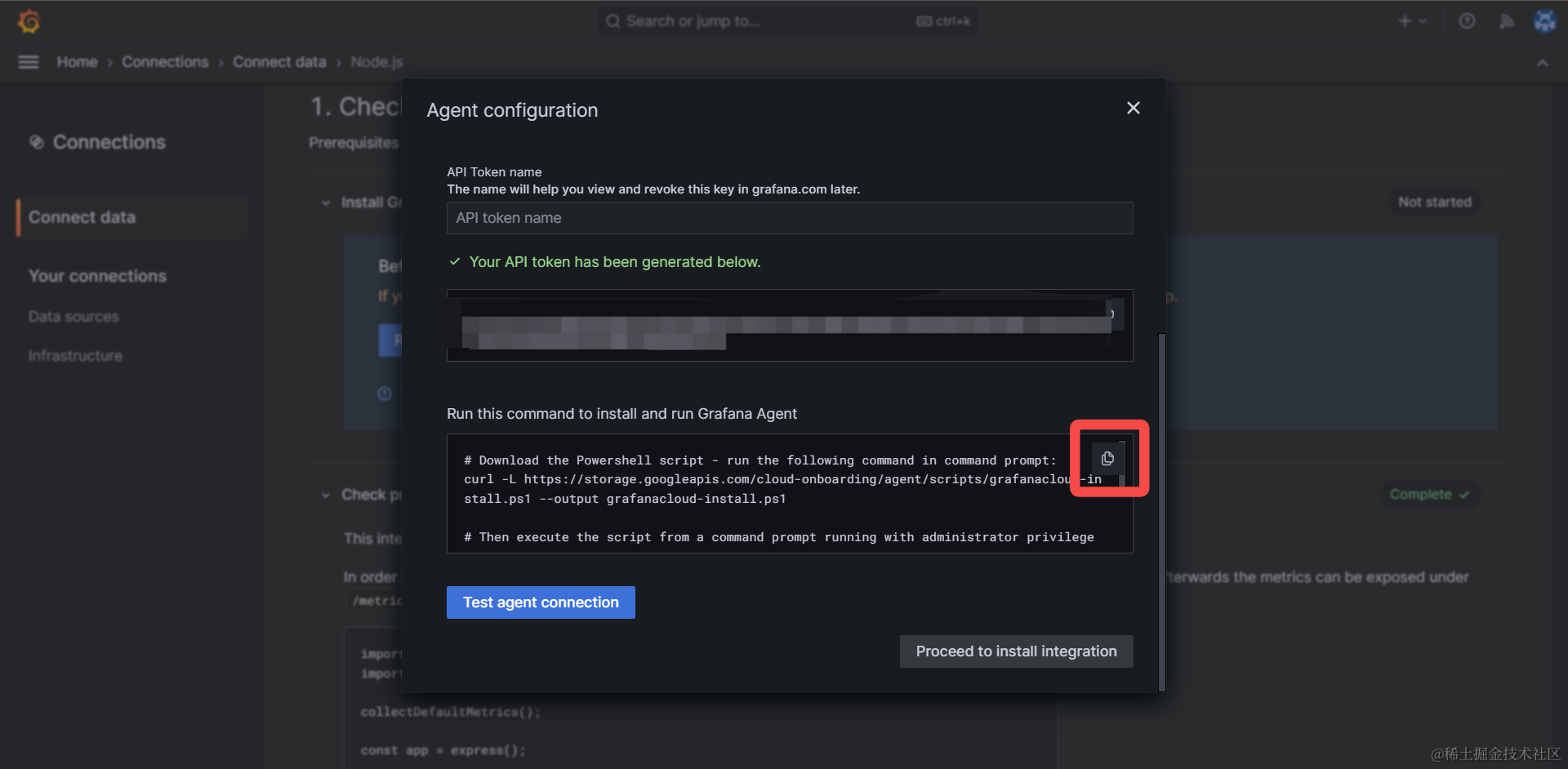
安装命令执行完成后,点击Grafana页面中,弹窗左下角的 Test agent connection 即可验证安装是否完成。
验证通过、安装完成,就可以在本地通过Node.js应用收集并上报数据了。
用命令行安装时常见问题及解决建议:
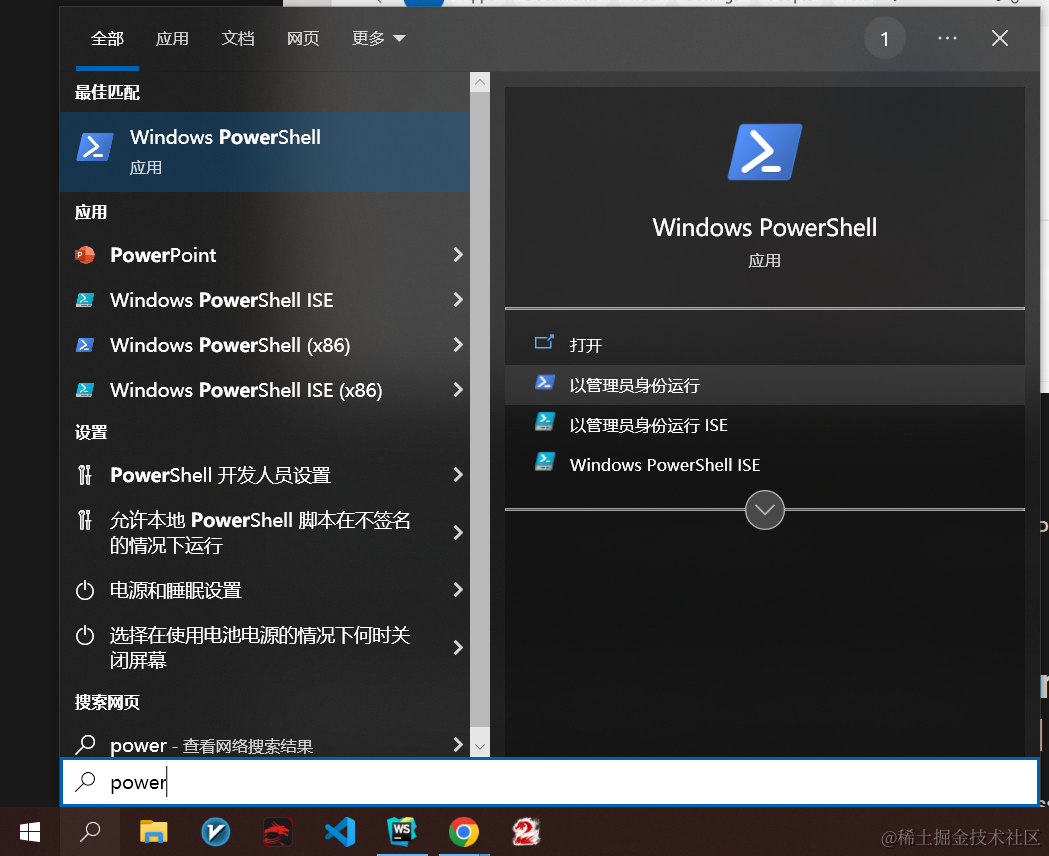
问题1:Windows系统 需要以管理员身份运行 PowerShell 才能顺利安装,运行方式如下图,在搜索框搜索时选择“以管理员身份运行即可”:
问题2:执行命令行时报错
curl: googleapis.com 443 Timeout。答:建议检查网络环境,确保科学上网应用到了全局,命令行也走网络代理。
问题3:无法确定agent是否成功安装、运行。
答:通过任务管理器应用,搜索Grafana Agent进程可以确认运行状态,如图:
2. 本地运行数据收集应用#
运行数据收集 Node.js 应用有2个选项。
1. 克隆数据收集示例应用:node-prometheus-grafana-demo#
我们可以直接 Clone 笔者编写的本书配套数据收集示例应用:https://github.com/JuniorTour/node-prometheus-grafana-demo
克隆后,运行也很简单,只需要执行:
npm install
npm run start2. 从头开始搭建数据收集应用#
也可以从头开始,新建一个空白 Node.js 项目,大致的步骤是:
- 创建新目录:node-prometheus-grafana-demo
- 执行
npm init初始化生成package.json,并添加启动脚本:"start": "node app.js" - 安装必要NPM包依赖:
npm install express prom-client - 新建
app.js,将官方的代码示例复制粘贴下来:
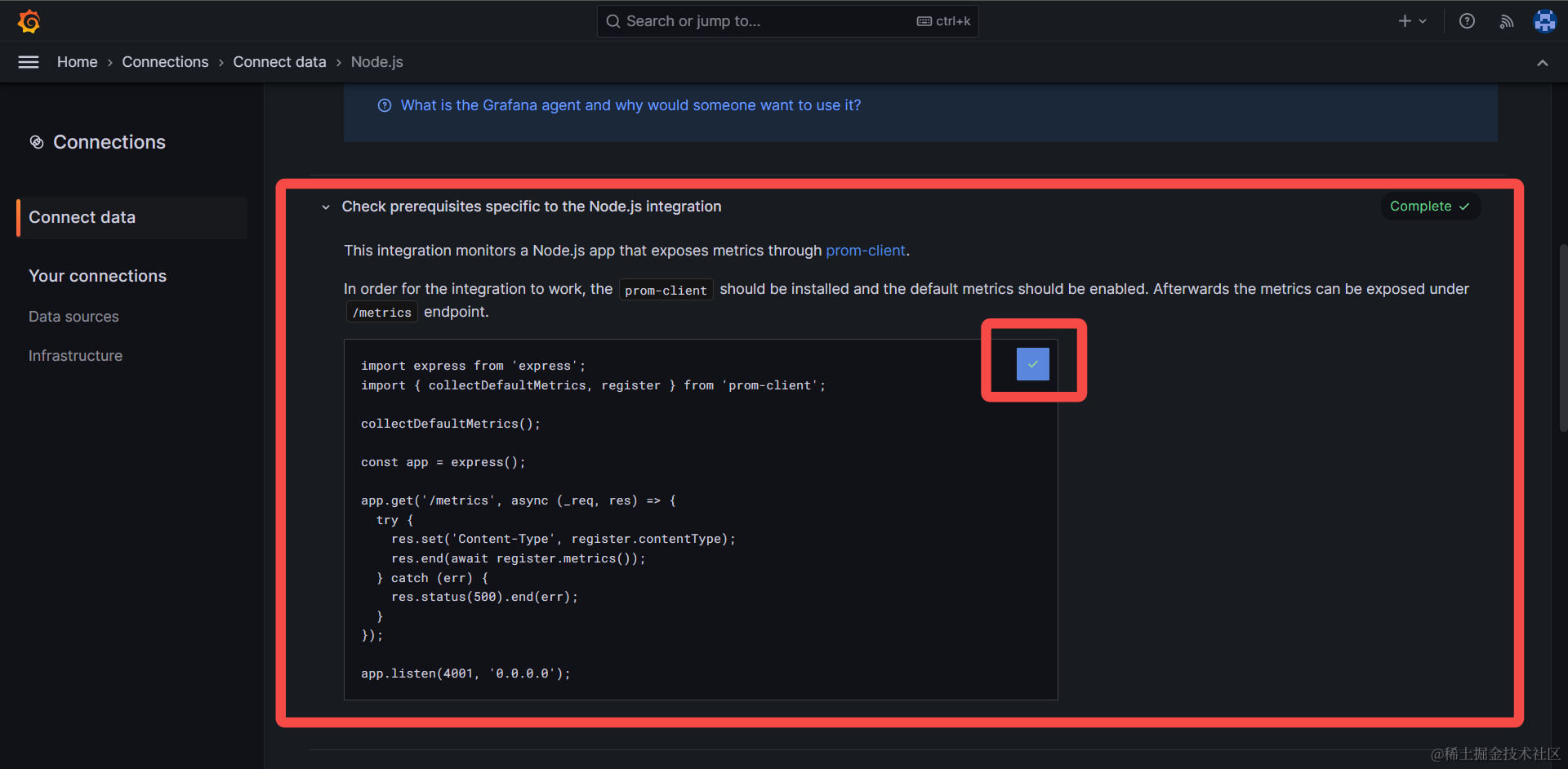
注:官方示例需要Node.js环境支持 ES module 语法,你也可以参考笔者提供的示例项目,使用更方便的 CommonJS module 语法:
完整代码示例《feat: 引入express && prom-client;初始化服务》commit:https://github.com/JuniorTour/node-prometheus-grafana-demo/commit/7ba9148a70164c944cd6d474251c5bef2507273c
运行 npm run start 后,prom-client就会自动开始采集一批默认的 Node.js 应用数据。
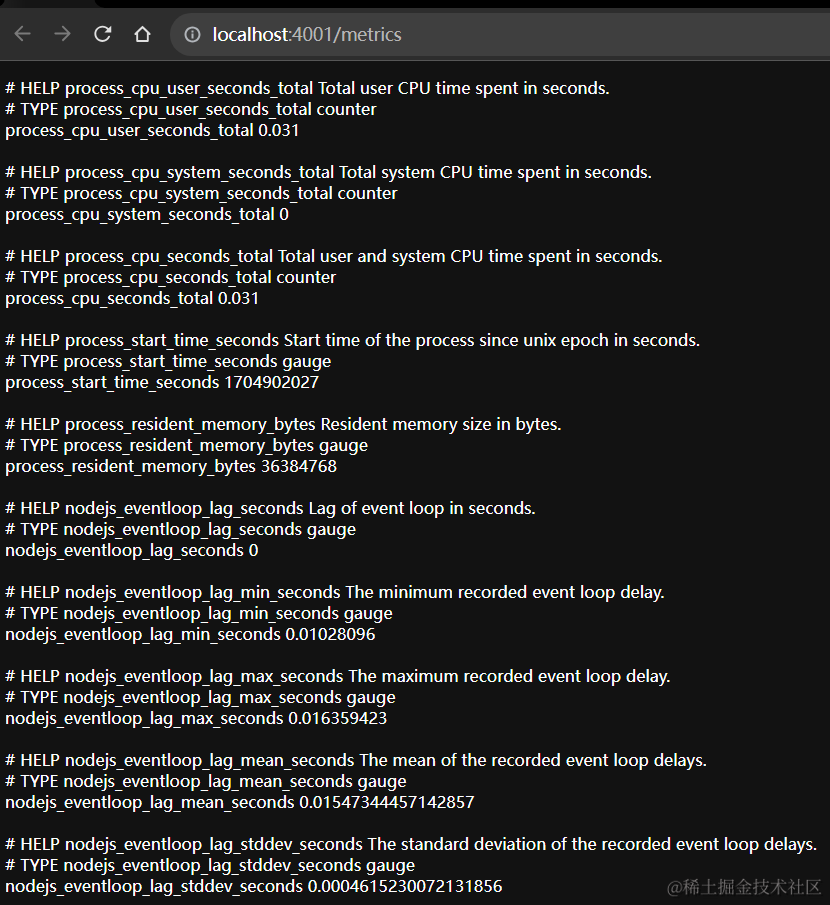
注:数据收集应用运行成功后,访问应用的
/metris接口,应该能看到页面展示了大量数据,这些就是Agent要刮取收集的数据,如图:
最后,让我们把预置的一批可视化图表,添加到我们的看板中,点击下图中的安装 Install 按钮:
3. 添加预置可视化图表#
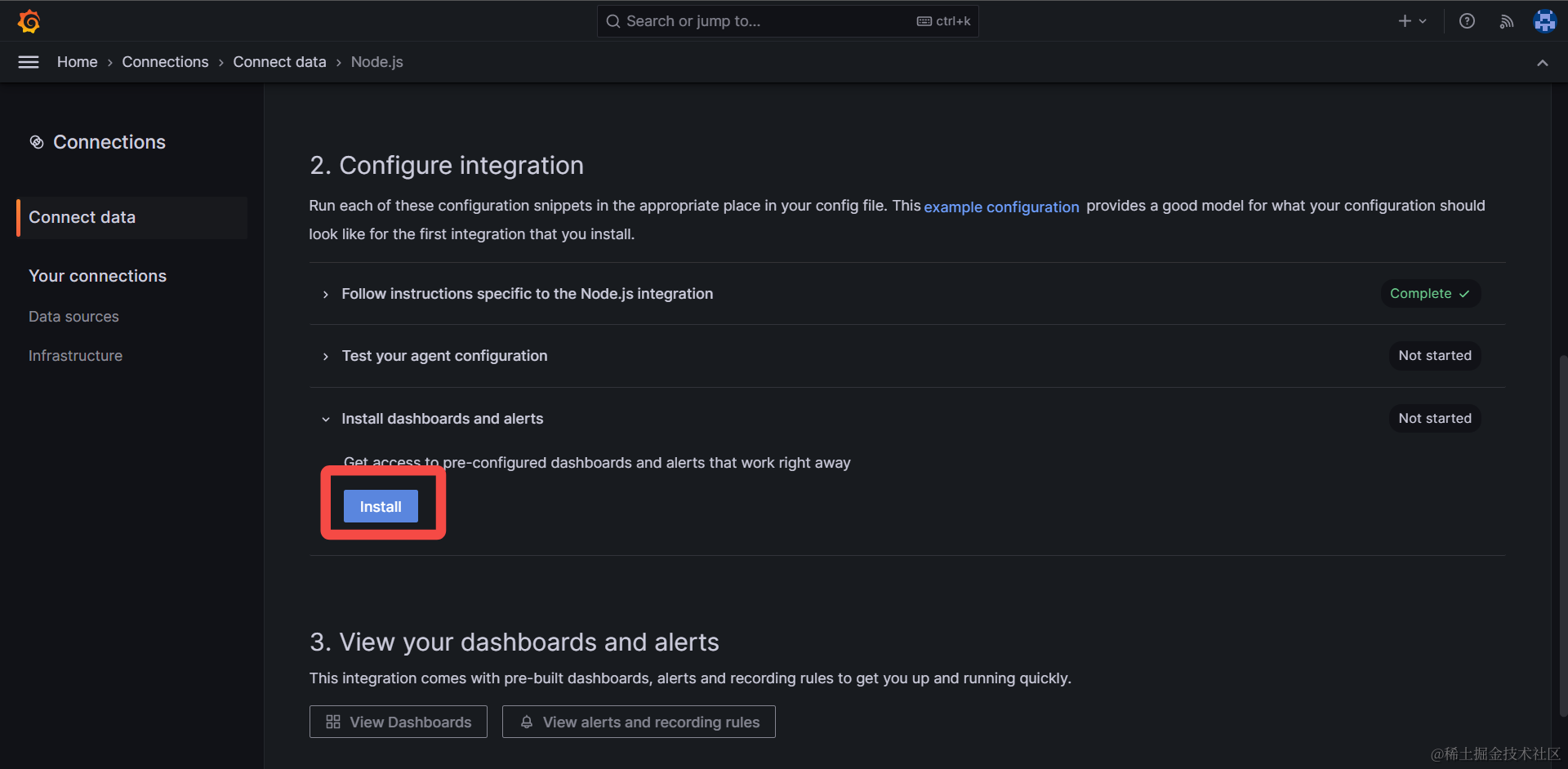
安装后,一套监控 Node.js 应用内存用量、CPU使用率等指标的可视化图片就会被添加到我们的看板中,本地收集的数据,也会随之显示出来,如下图:
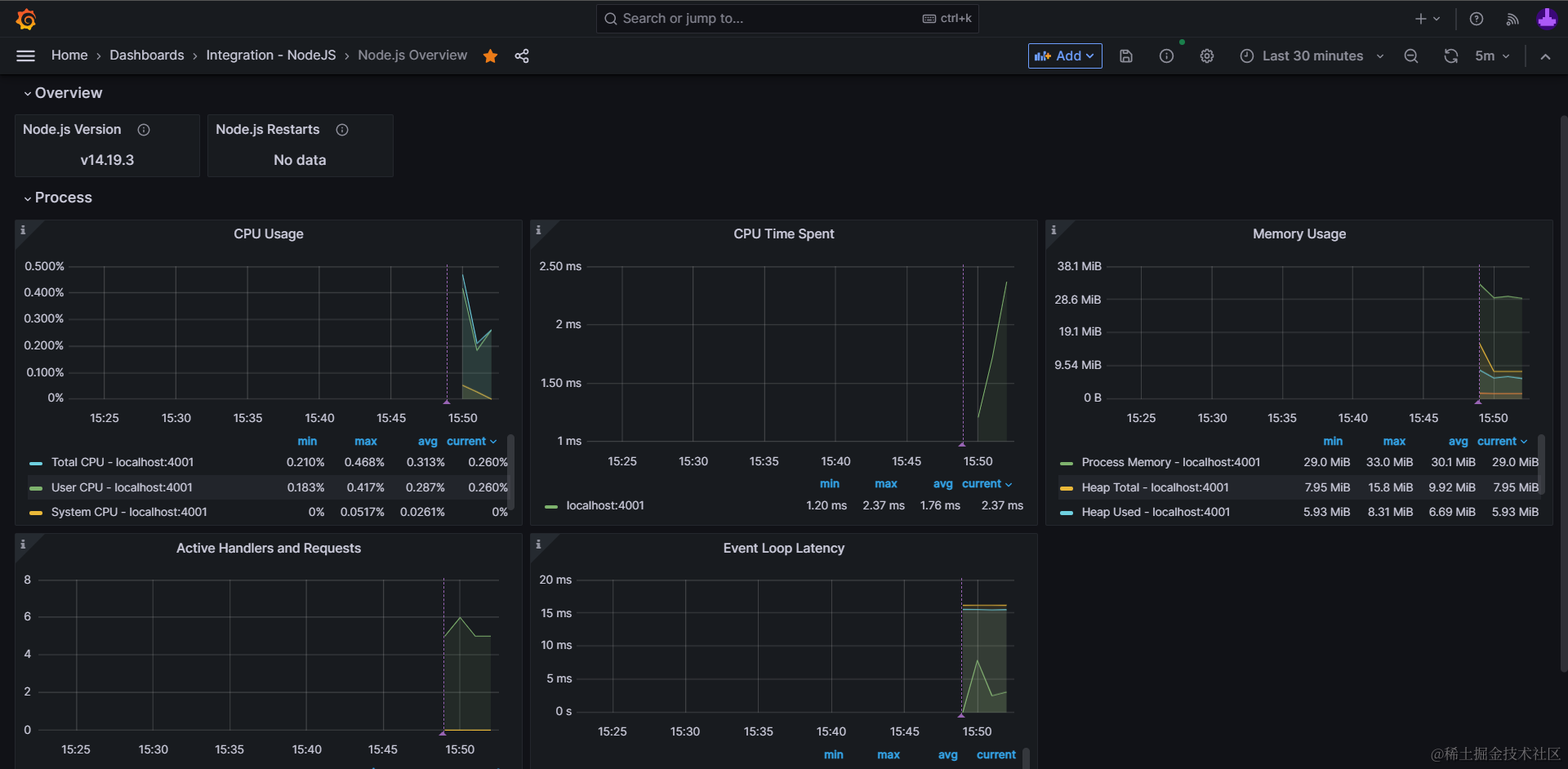
Grafana 官方 Node.js 集成文档:https://grafana.com/docs/grafana-cloud/data-configuration/integrations/integration-reference/integration-nodejs/
各大云服务供应商也有集成 Grafana:
我们的目标不只是监控这些基础指标,下面让我们试试如何增加自定义指标。
3. 上报自定义指标并创建可视化图表#
为了将前端收集到的web-vitals数据,发送到Grafana,后端服务需要基于prom-client的能力,增加一批自定义指标。
1. 搭建后端服务器接收指标数据#
让我们继续在app.js中添加以下代码:
完整代码实现,请参考 node-prometheus-grafana-demo 示例项目中的《feat: 增加自定义计数指标及接口》commit
src/app.js
// ...
const app = express();
/* 1. */
const metricPath = '/metrics';
app.get(metricPath, async (_req, res) => {
try {
res.set('Content-Type', register.contentType);
res.end(await register.metrics());
} catch (err) {
res.status(500).end(err);
}
});
/*
2. 新增POST方法接口,接收客户端传来的任意自定义指标
*/
app.post('/counter-metric', function (req, res) {
const { name, help, labels } = req.body;
if (!name) {
console.warn(
`/counter-metric WARN: no name req: ${JSON.stringify(req.body, null, 2)}`
);
return;
}
useCounter({ name, help, labels });
const message = `/counter-metric name=${name} labels=${JSON.stringify(
labels
)}`;
console.log(message);
res.status(200).json({ message });
});src\prom-client.js:
const client = require('prom-client');
const Registry = client.Registry;
const register = new Registry();
client.collectDefaultMetrics({ register });
function useCounter({ name, help, labels }) {
/* 3. */
let counter = register.getSingleMetric(name);
if (!counter) {
counter = new client.Counter({
name,
help,
registers: [register],
labelNames: Object.keys(labels),
});
}
counter.inc(labels, 1);
}
module.exports = {
useCounter,
register,
};通过这2段代码,我们实现了以下功能逻辑:
- 新建了一个Express框架的Node.js服务器应用,用于和其他应用以HTTP接口的形式通信,获取数据,再上报到Grafana。
- 增加了GET方法的HTTP接口
/metrics,用于供Grafana Agent获取该服务器应用收集到的数据,Grafana Agent定时请求该接口,收集这段时间的数据,并转发到Grafana服务器上。
Grafana文档中,把Grafana Agent通过
/metrics收集数据的过程为刮取(scrape) ,非常生动形象。
- 增加了另一个POST方法的HTTP接口
/counter-metric,用于接受其他应用上报的数据,在本节中主要用于接收前端应用发送来的web-vitals数据; - 在
src\prom-client.js中封装prom-client的new client.Counter(),以便于我们在/counter-metric接口中调用,记录计数类型的数据。
每次有请求发送到服务器,都会触发计数器指标加一(couter.inc(labels, 1);),并且会通过labels字段记录上报的各种自定义数据,例如名称(name)、评分(rating)等;
有了这部分代码,我们就可以从前端应用中上报数据到Grafana,例如:
// 客户端发送数据用法:
await fetch('http://localhost:4001/counter-metric', {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
name: 'FCP',
help: 'FCP data',
labels: {
rating: 'good',
// num: Math.random() * 100,
// bool: Math.random() < 0.5,
}
}),
})综上所述,完整数据收集流程即:
- 前端应用通过HTTP异步请求,将
web-vitals数据发送到数据收集后端服务; - 数据收集后端服务调用
prom-client的自定义计数指标记录数据到内存中; - Grafana Agent 应用,定期通过
/metric接口刮取数据,上报到 Grafana 远端服务器;
接下来我们可以基于之前的《获取web-vitals数据在线 DEMO》: https://output.jsbin.com/bizanep 学习从前端应用上报数据到 Node.js 数据收集后端服务的逻辑。
2. 增加前端上报数据逻辑#
我们的改动主要有2部分:
- 增加
report方法,用于把调用web-vitals库API获得的数据,通过HTTP请求到发送到数据收集后端应用的/counter-metric接口,并附带name, rating这2个字段作为请求体,以便我们在Grafana中查询过滤,实现想要的可视化效果; - 在DEMO已有的
onGetWebVitalsData方法中增加report()方法的调用,将指标数据中的name, rating作为参数传入;
对应代码如下:
async function report(name, labels, help = 'default help') {
await fetch('http://localhost:4001/counter-metric', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
name,
help,
labels,
}),
});
}
function onGetWebVitalsData(data) {
// ...
report(name, { rating});
}完整示例请参考 《发送 web-vitals 数据 DEMO》:https://output.jsbin.com/xibimaj/1
运行这些新增改动后,我们就能在开发中工具的Network面板中看到发送数据的HTTP请求,以及数据收集后端应用的响应了:
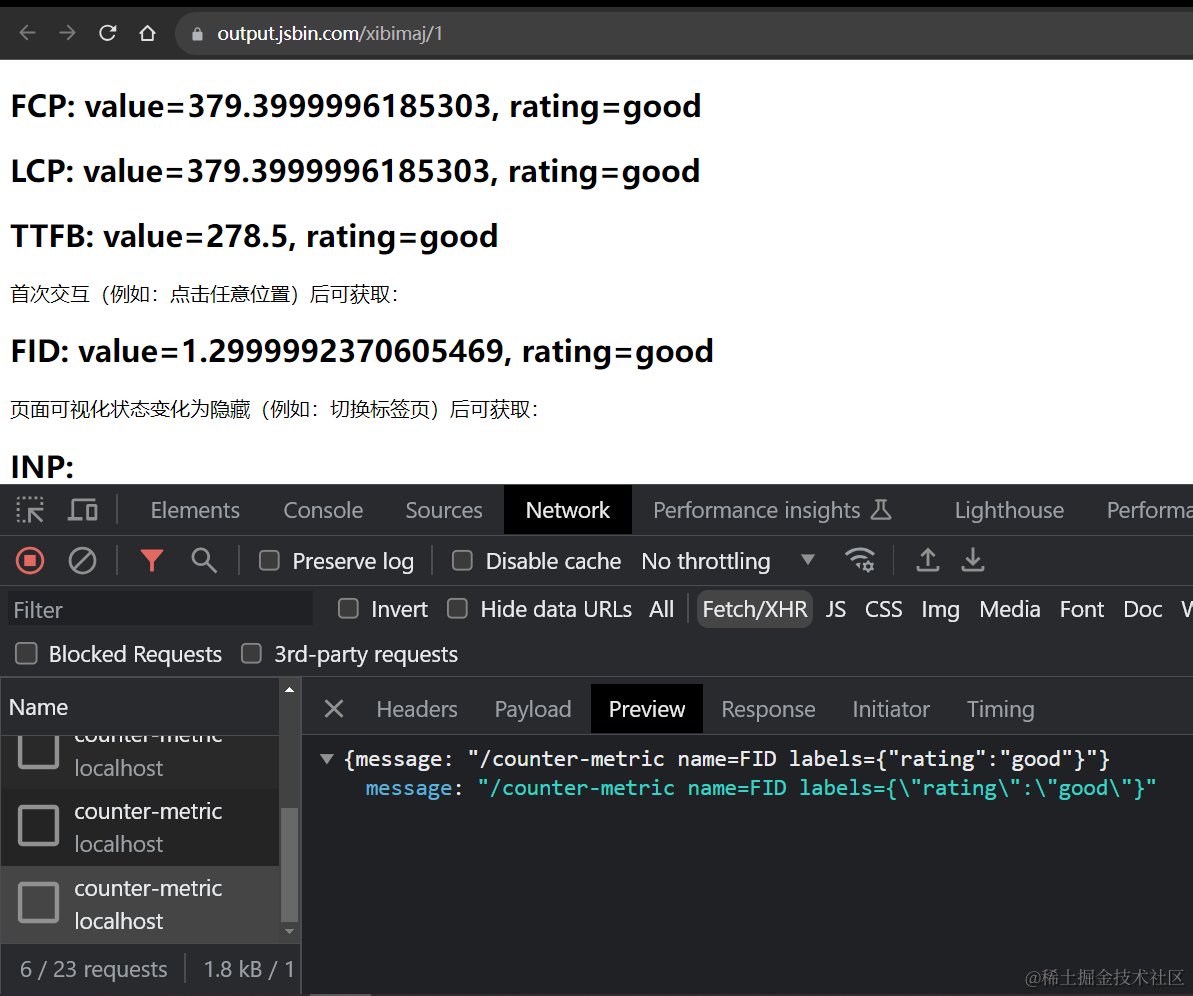
有了这样一套前后端工作流,我们的web-vitals数据就可以方便地发送到 Grafana,让我们能基于这些数据创建出各式各样的可视化图表。
4. 创建 Grafana 可视化图表指南#
创建一张 Grafana 可视化图表,非常简单,主要有以下几步:
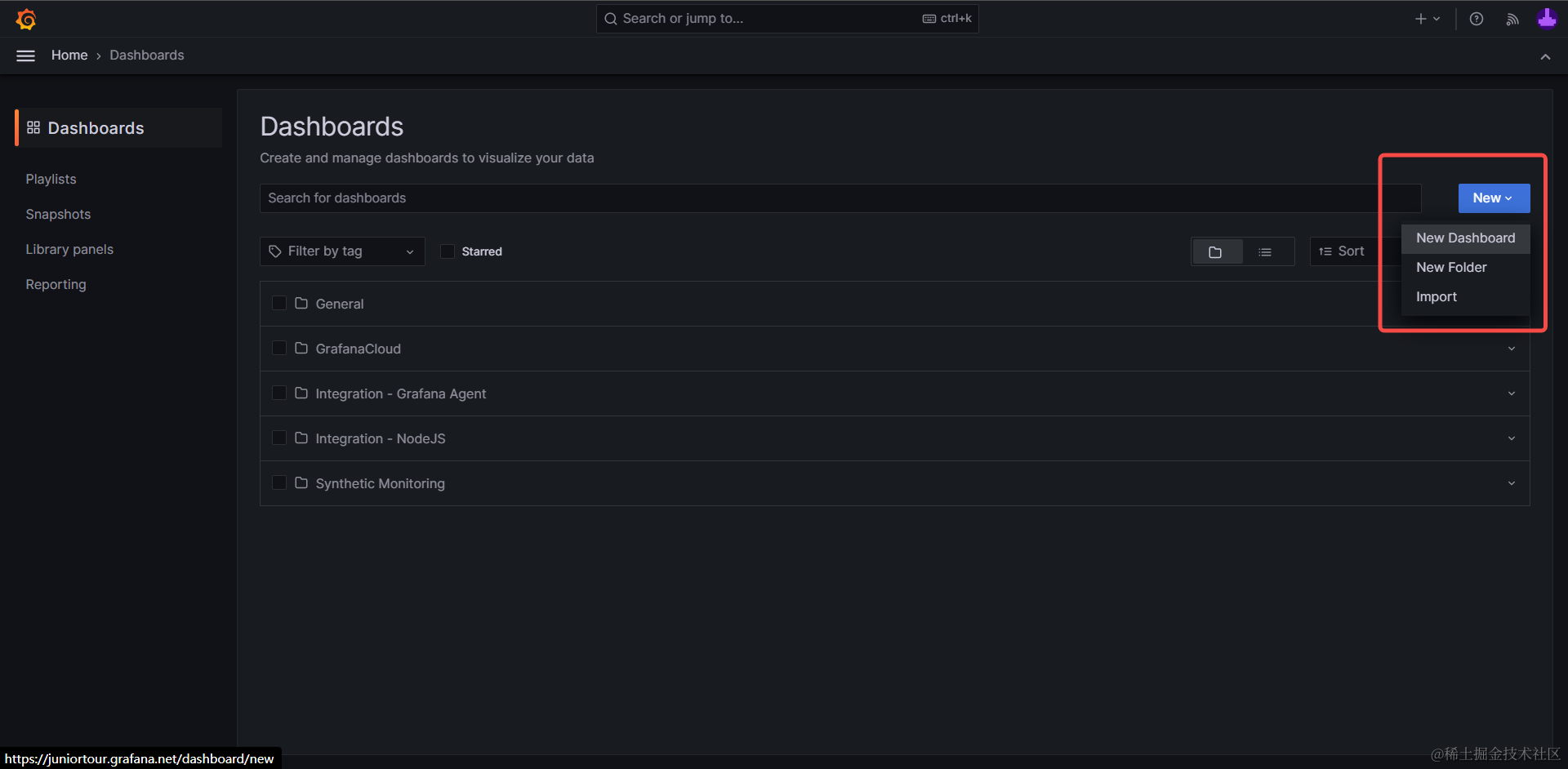
1. 新建仪表盘页面#
首先,让我们访问仪表盘(Dashboard)页面,点击新建仪表盘(New Dashboard)按钮,创建一个专门的目录,存放我们创建的可视化图表。
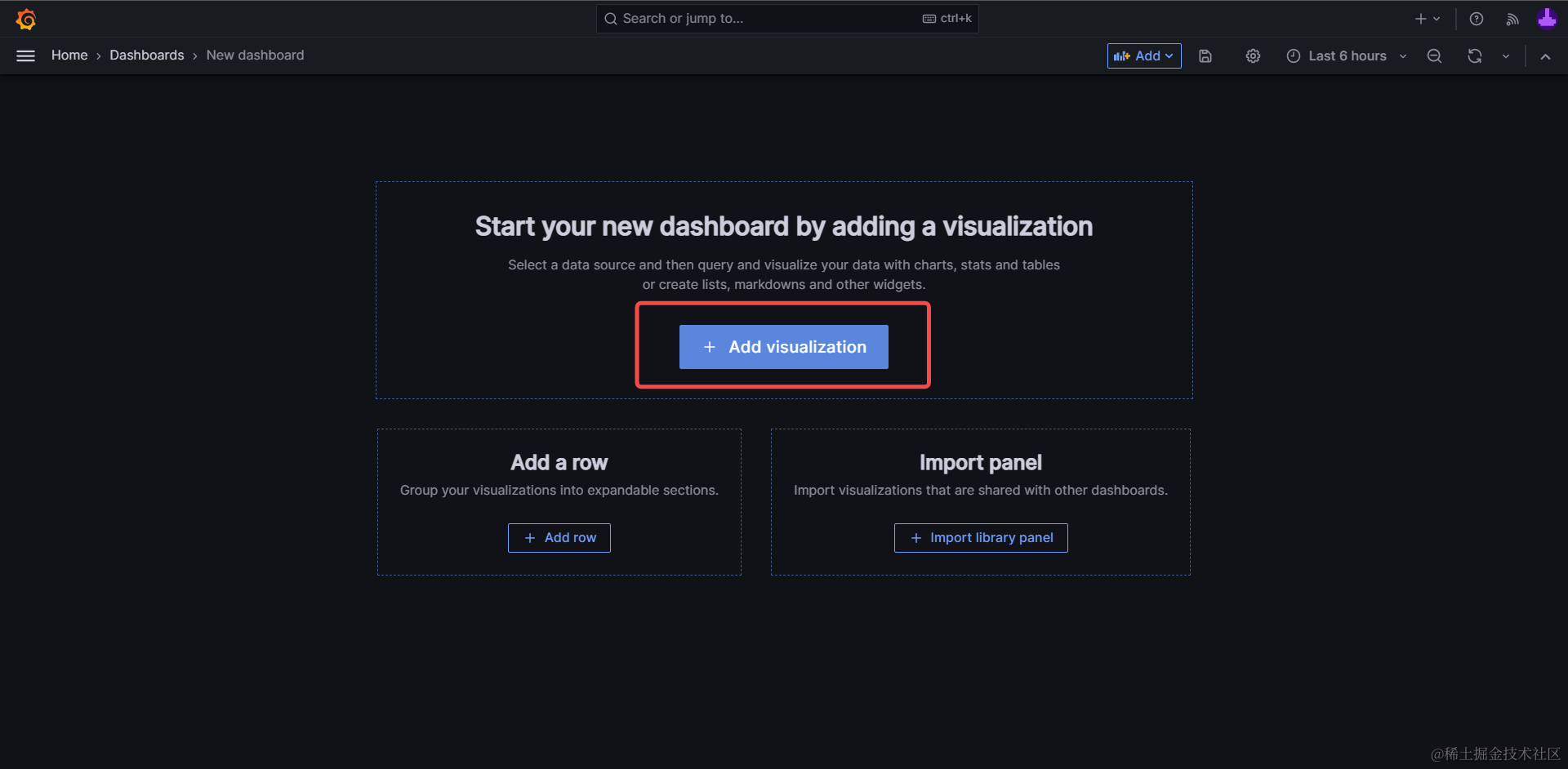
2. 新增可视化(Add visualization)图表#
接下来,点击新增可视化图表(Add visualization)按钮,我们就会进入到图表的编辑页面
3. 选择数据源#
一张可视化图表要绘制出数据,首先就要确定数据的来源,所以进入图表编辑页后,我们首先要选择的就是这张图表的数据源(Data Source):
如果按照上文的接入演示一路操作过来,会有默认的数据源:grafanaclound-${yourName}-prom,这就是我们的数据收集后端应用上报数据对应的数据源,选中即可。
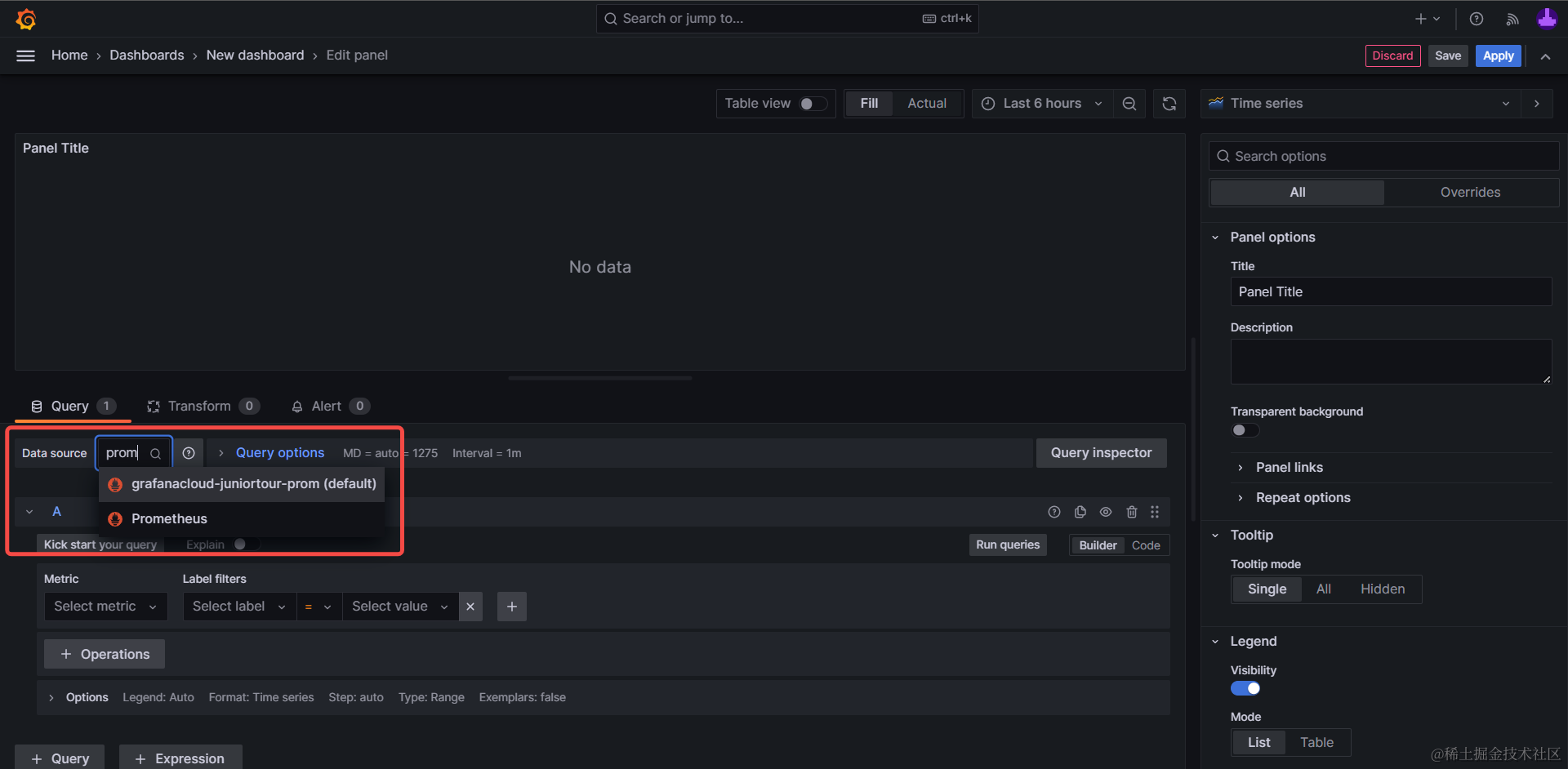
4. 输入查询语录#
Grafana 中不同的数据源对应不同的查询器面板及语法,我们以前文示例中 prom-client对应的 Prometheus 数据源为例,其主要有2种模式:
- 交互界面选择查询语句(Builder)
- 直接输入查询语句文本(Code)
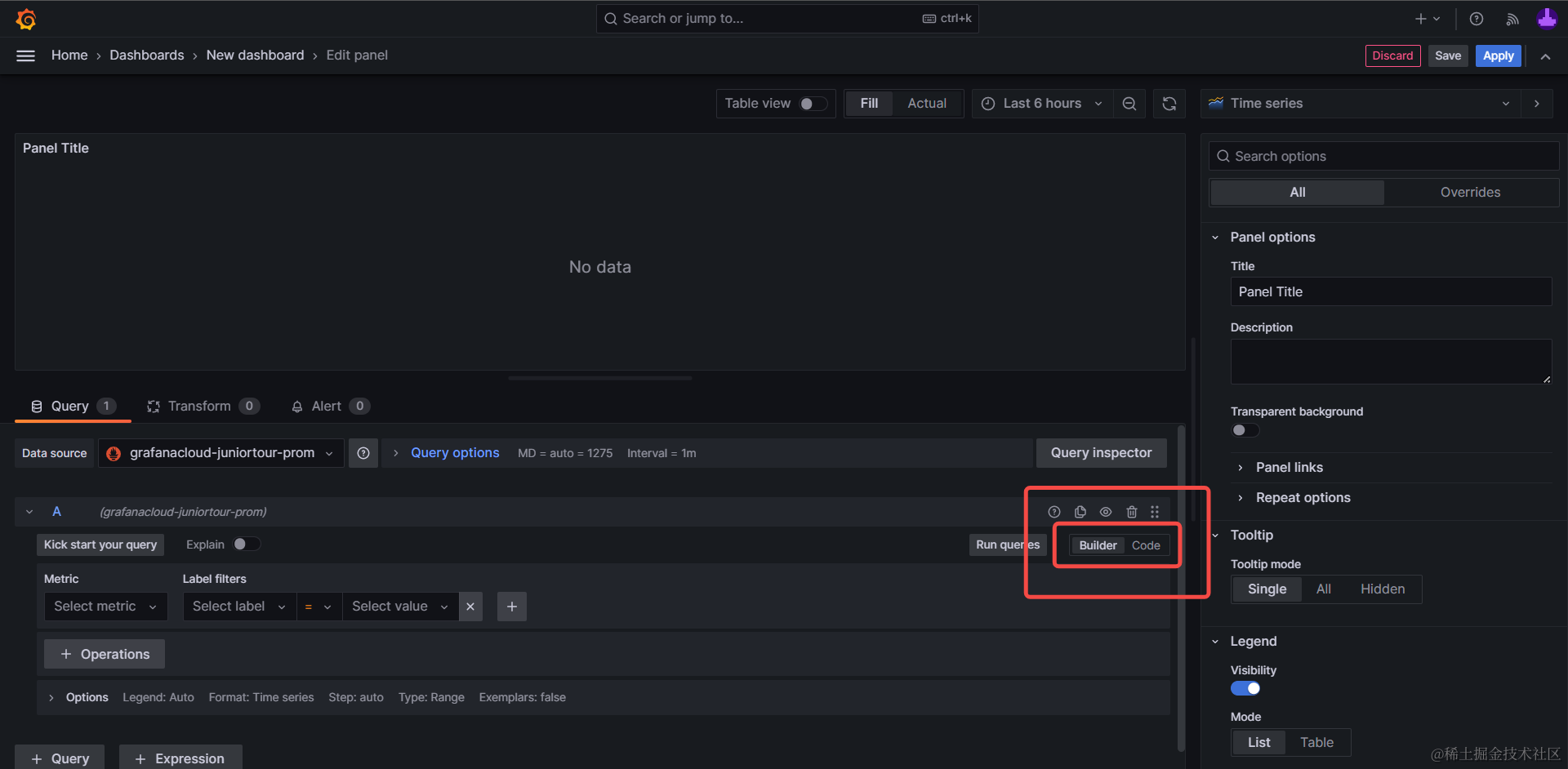
推荐使用对新用户更为友好的Builder模式,可以看到主要包含2类选项:
- 指标(Metric)
- 标签过滤(Label filters)
分别对应我们上文中服务端调用prom-client的 new Counter API 时传入的name,labels字段:
我们分别输入并选择FCP{rating=~"good"}三项后,点击刷新仪表盘(Refresh Dashboard)即可看到我们刚刚上传的数据,将对应时段有多少个name=FCP且rating=good 的上报数据在可视化图表中展示出来:
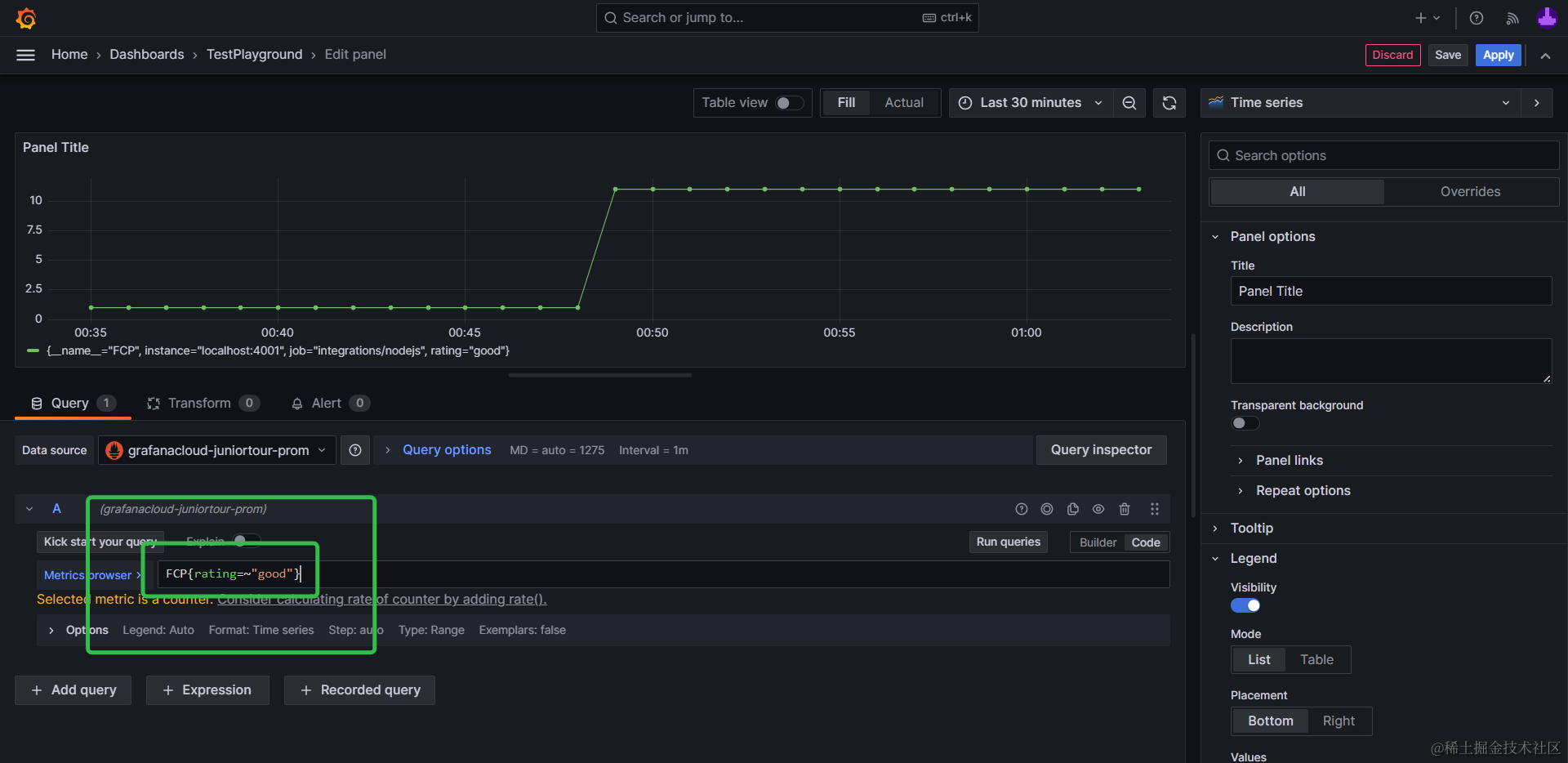
熟悉了基础的指标和标签后,还可以探索一下运算 Operation功能,类似于给数据加函数处理,进行加减乘除等聚合处理,也是常用的功能。
注:不同的数据源有各自不同的查询面板UI和语法:
- Prometheus 数据源查询语法:https://prometheus.io/docs/prometheus/latest/querying/basics/
- ElasticSearch 数据源查询语法:http://lucenetutorial.com/lucene-query-syntax.html
5. 调整样式、配置等细节#
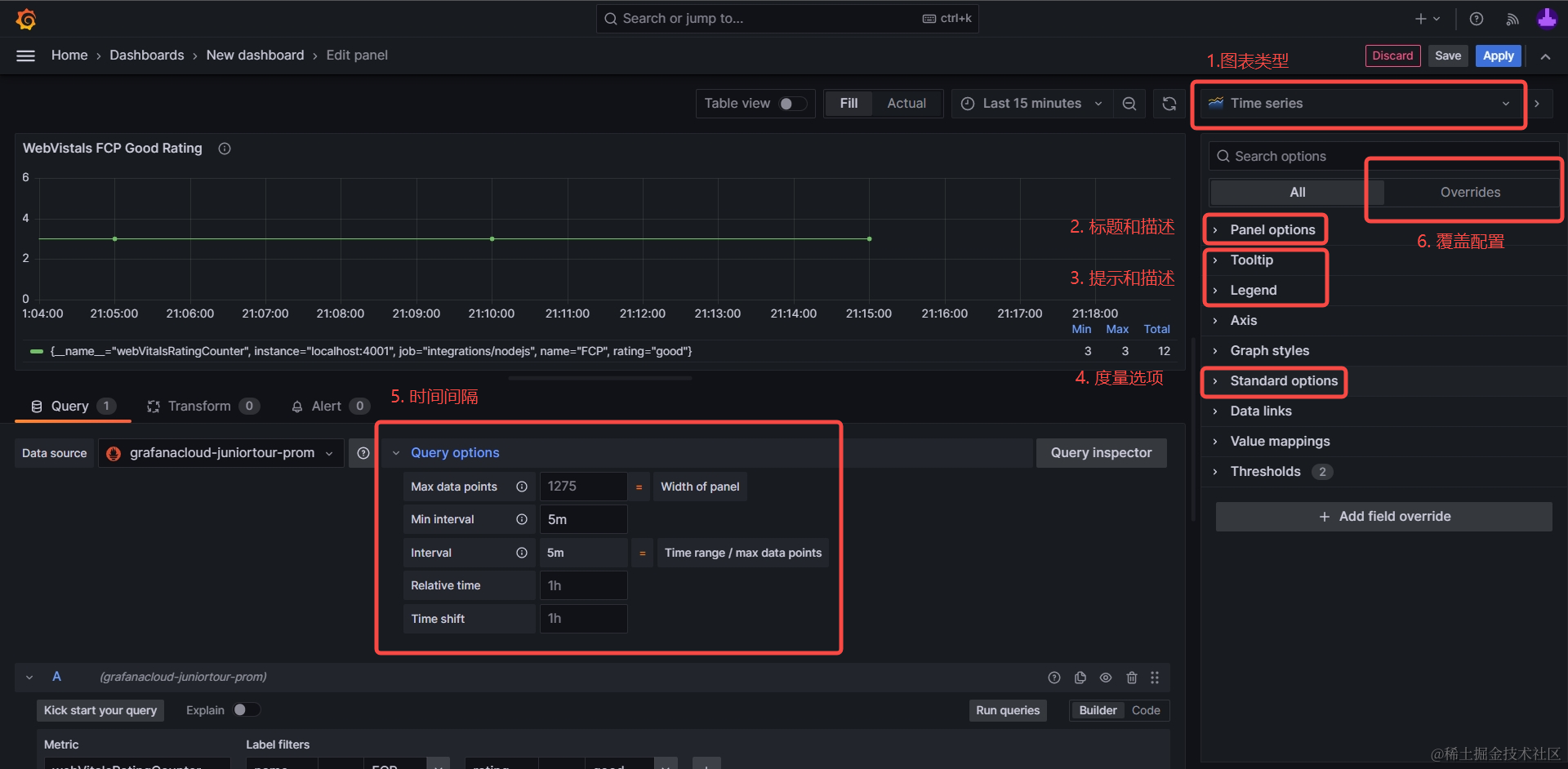
有了数据后,我们就可以进一步完善可视化图表的细节,常用的功能主要有6个:
图表类型:常用的有折线图、柱状图,纯文本;
标题和描述
提示(Tooltip)和图例(Legend):设置何时显示鼠标悬停时的提示框,以及图例的样式和内容;
度量选项(Standard Options):设置当前查询的值是什么单位,常用的有:
- 其他-短数值(Misc / short):会对数值进行进位处理,例如1000000,会被优化成 1M。
- 其他-百分比(Misc / Percent(0.0-0.1))
- 时间-毫秒(Time/ millisecond)
时间间隔:设置将多久的时间间隔内的所有数据,聚合数据为可视化图中的一个数据点。
例如截图中5m即表示将5分钟内的数据统一计入可视化图中的一个点。
所以下图中时间范围(Time Range)选择最近15分钟(Last 15 minutes),对应折线图就有3个点。
- 覆盖配置:覆盖查询语句默认的显示名称、颜色等配置。
以上各项配置是个人总结较为常用的配置项,可以自由尝试调整,观察效果。
6. 分别保存图表和仪表盘#
完整保存图表,需要先后点击:
- 图表编辑界面的右上角的应用(Apply)按钮,保存图表;
- 仪表盘页面的保存仪表盘按钮,保存整体仪表盘。在此处可以输入仪表盘的名称及所属目录;
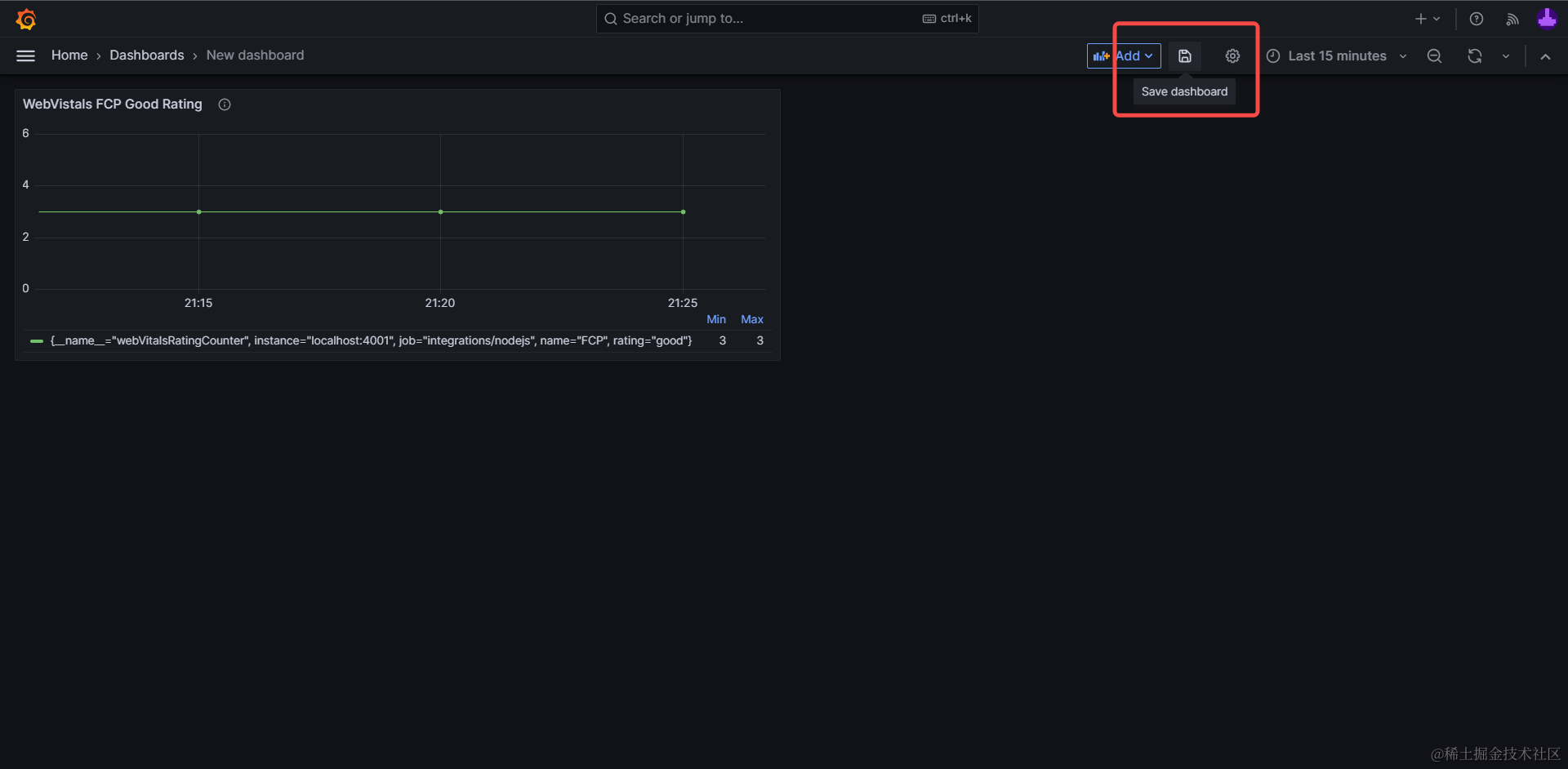
至此,我们就创建了第一张可视化图表,后续可以在实践中逐步熟悉 Grafana 的强大功能,这只是我们的第一步。
这一套数据收集方案,也可以用于收集用户行为数据,例如页面访问量(Page View),每个按钮的点击量等业务数据。
将数据记录并可视化,可以让我们明确的感知到工作的产出,帮助我们在工作中获得成就感。
当我们的数据和图表越来越多,我们对维护项目的了解也会越来越深入,更有助于我们用数据驱动开发、促进体验优化、推动业务发展。
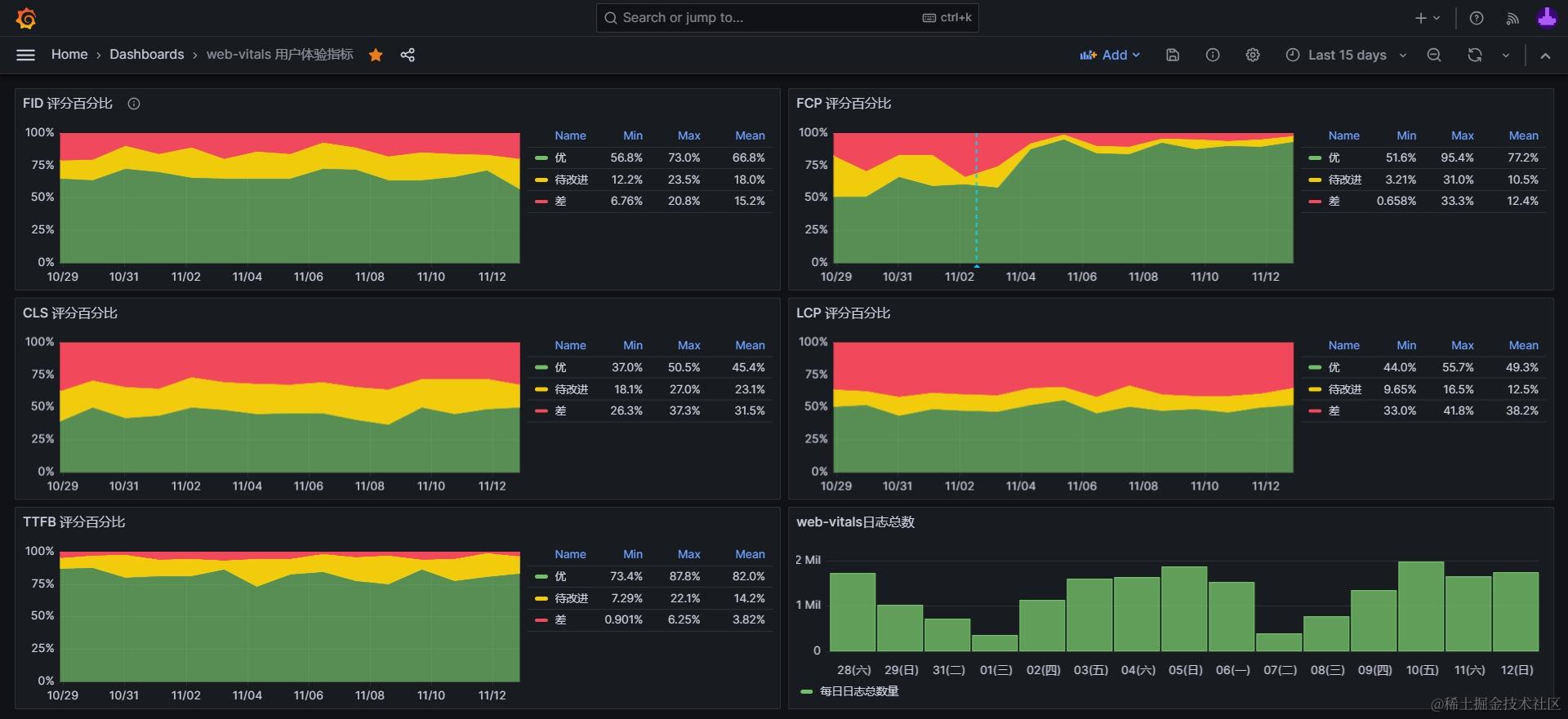
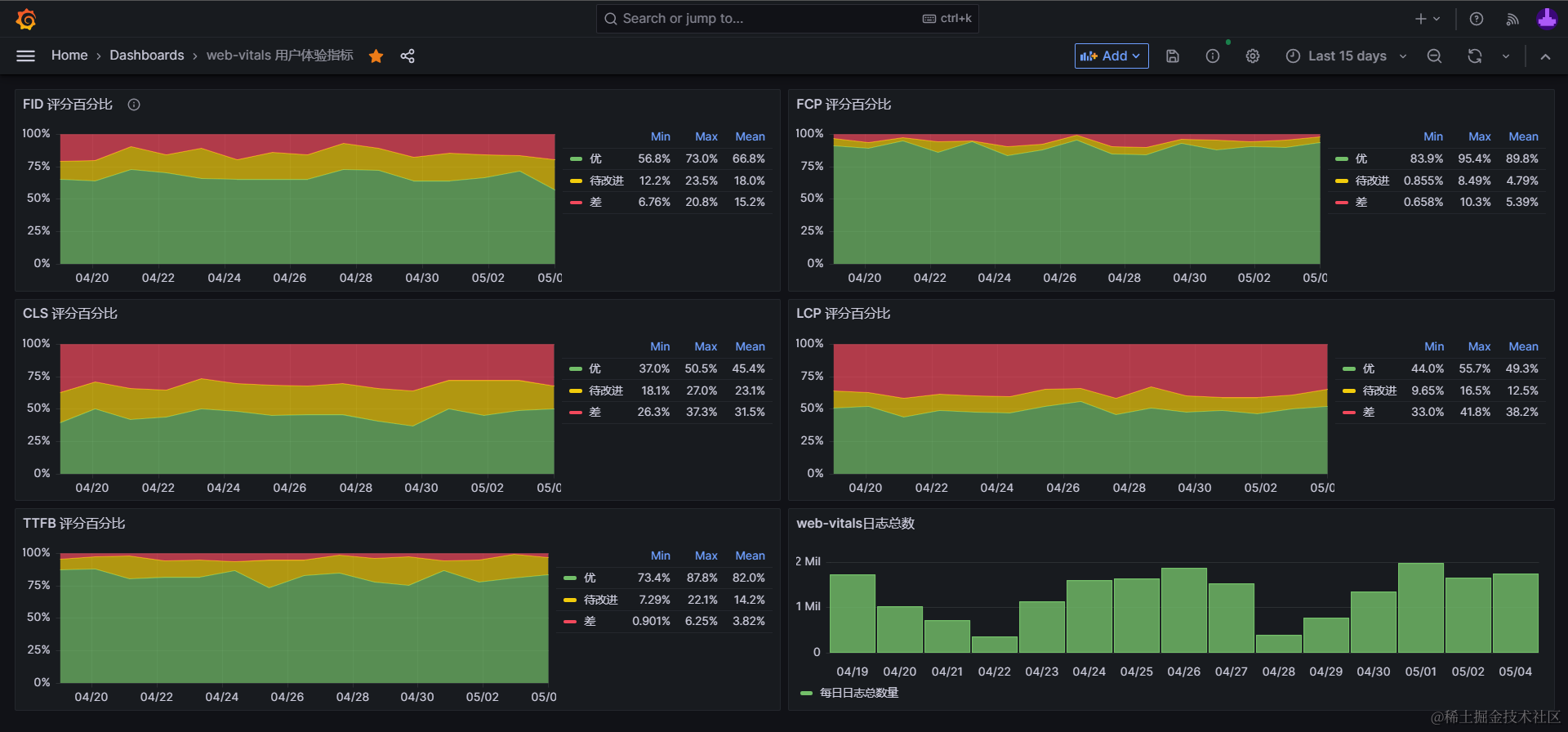
5. 堆叠百分比评分图优点及示例#
从web-vitals获得的比较有统计意义的数据主要有:
- 各指标的数值(
value),例如累计布局变化CLS的 0.2; - 评分(
ratings):按官方标准对值进行划分得到的字符串值,共有优('good'),待提升('needs-improvement'),差('poor')三类值,可用于对数据进行标准化处理; - 指标的统计来源(
sources):记录了计算各指标的来源,例如累计布局变化CLS的sources字段记录的就是每次意外布局变化对应的DOM元素,及其变化前后的位置尺寸数据;
例如这条通过onFCP()API获取的LCP数据:
{
delta: 382.80000019073486
entries: [
{
duration: 0
element: p
entryType: "largest-contentful-paint"
id: ""
loadTime: 0
name: ""
renderTime: 382.8
size: 8985
startTime: 382.80000019073486
url: ""
}
]
id: "v3-1683034382854-2926018174544"
name: "LCP"
navigationType: "reload"
rating: "good"
value: 382.80000019073486
}笔者更推荐使用评分字段(ratings) 作为可视化图表的主要量化指标。
原因是直接使用值(value) 作为统计数据,计算其平均值或最大最小值,这样做常常会遇到异常波动的问题,即在前端项目没有任何变更的情况下,却观察到值产生了显著的波动变化。
波动的原因一般是因为web-vitals在生产环境中,因为千差万别的用户环境,获取的值(value) 的波动范围较大,个别极端值会导致统计出的平均值显著变化。
而使用评分字段(ratings) 作为指标,相当于对观测的值做了一次标准化处理,将一定范围内的值处理成统一的评分,有助于规避个别极端值导致的异常波动。
笔者最初基于web-vitals制作数据可视化图时,用的就是值字段,计算了FCP等指标的平均值,观察一段时间后发现即使前后端项目没有上线变更,各指标的平均值也会有10%以上的波动,这显然是不符合预期的,这种波动将会降低我们评估优化效果的准确性。
例如下图,04-22 前后的 LCP 平均值在我们的前端项目没有变更的情况下,就出现了减少11%的变化,这样的异常波动显然不利于评估我们优化的效果:
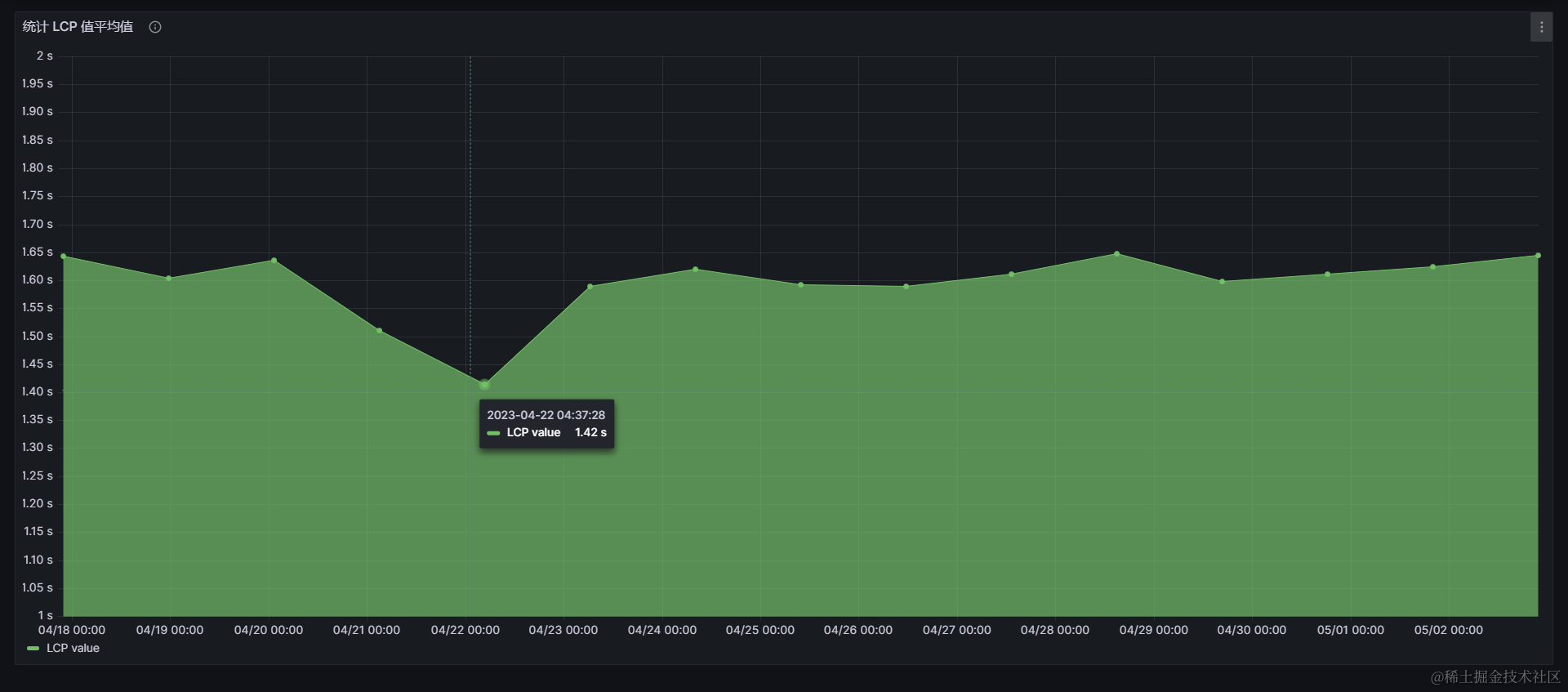
后来改成基于评分字段(ratings) 制作各评分占比堆叠百分比图后,数据异常波动问题就不再出现了,各评分的占比平均值在长时间内都能保持不超过5%的波动。
这样当我们主动进行一些优化后就能观察到更客观,更有说服力的指标变化。
下面分享一套基于模拟数据的“堆叠百分比图”示例及配置源码,各位读者可以根据需要复制粘贴到自己的仪表盘内,并替换为真实数据,从而得到客观稳定的优化效果评估指标。
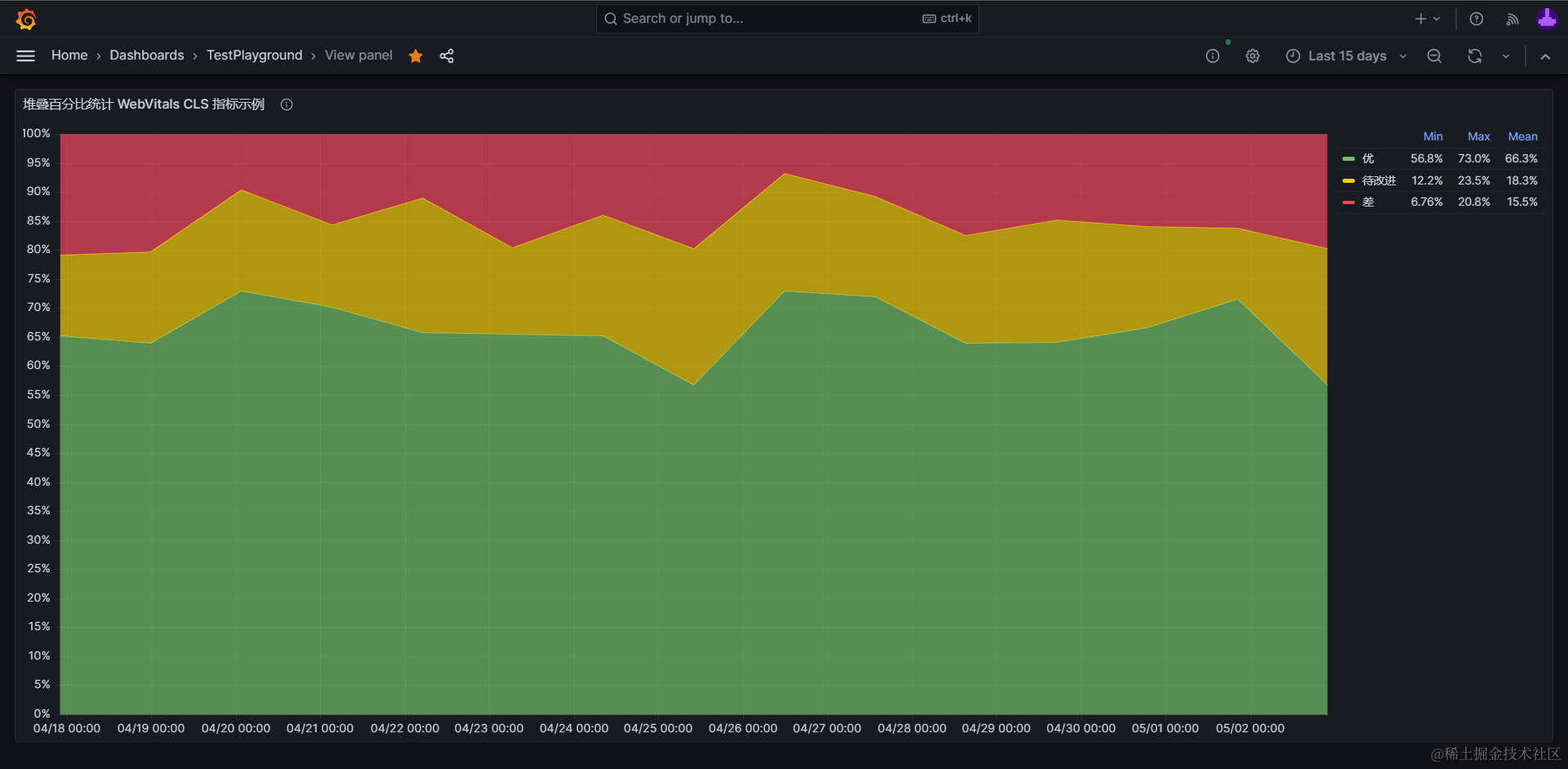
1. 堆叠百分比图配置源码#
粘贴图表方式: 创建一张空图表后,点击更多选项-Inspect-Panel JSON,粘贴上述配置源码,点击应用(Apply)后即可立即生效
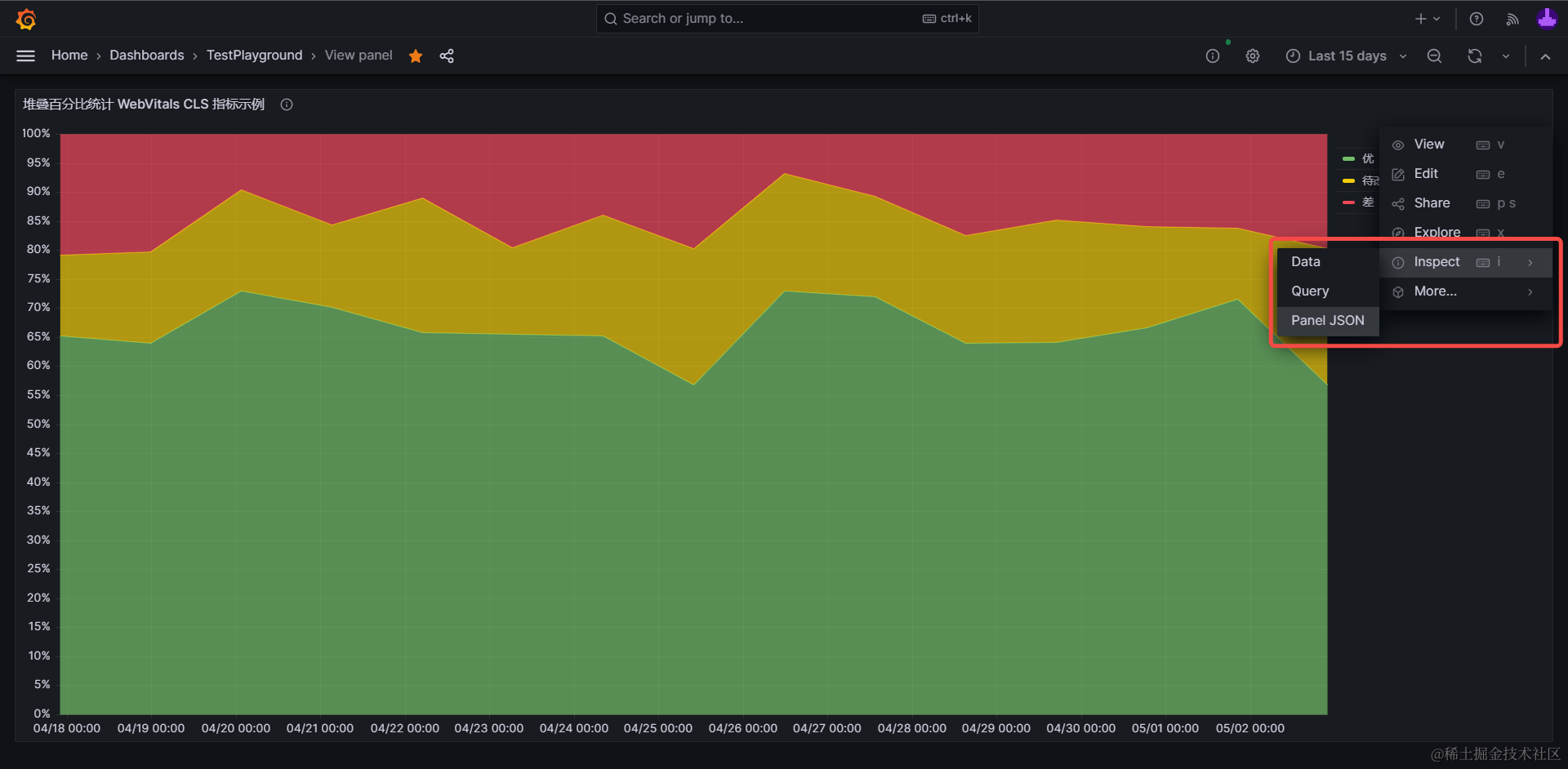
▶点击展开:“堆叠百分比图”配置源码
{
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"description": "“堆叠百分比图”配置源码,作者:https://github.com/JuniorTour",
"fieldConfig": {
"defaults": {
"custom": {
"drawStyle": "line",
"lineInterpolation": "linear",
"barAlignment": 0,
"lineWidth": 1,
"fillOpacity": 70,
"gradientMode": "none",
"spanNulls": false,
"showPoints": "auto",
"pointSize": 1,
"stacking": {
"mode": "normal",
"group": "A"
},
"axisPlacement": "auto",
"axisLabel": "",
"axisColorMode": "text",
"scaleDistribution": {
"type": "linear"
},
"axisCenteredZero": false,
"hideFrom": {
"tooltip": false,
"viz": false,
"legend": false
},
"thresholdsStyle": {
"mode": "off"
}
},
"color": {
"mode": "palette-classic"
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
},
"max": 1,
"min": 0,
"unit": "percentunit"
},
"overrides": [
{
"matcher": {
"id": "byName",
"options": "G"
},
"properties": [
{
"id": "color",
"value": {
"fixedColor": "red",
"mode": "fixed"
}
},
{
"id": "displayName",
"value": "差"
}
]
},
{
"matcher": {
"id": "byName",
"options": "E"
},
"properties": [
{
"id": "displayName",
"value": "优"
}
]
},
{
"matcher": {
"id": "byName",
"options": "F"
},
"properties": [
{
"id": "displayName",
"value": "待改进"
}
]
}
]
},
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 16
},
"id": 4,
"options": {
"tooltip": {
"mode": "multi",
"sort": "none"
},
"legend": {
"showLegend": true,
"displayMode": "table",
"placement": "right",
"calcs": [
"min",
"max",
"mean"
]
}
},
"targets": [
{
"alias": "good",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "A",
"scenarioId": "csv_metric_values",
"stringInput": "47,57,46,54,54,57,47,46,54,54,55,52,46,53,46"
},
{
"alias": "needsImprove",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "B",
"scenarioId": "csv_metric_values",
"stringInput": "10,14,11,11,19,13,15,19,15,13,16,17,12,9,19"
},
{
"alias": "poor",
"datasource": {
"type": "testdata",
"uid": "a95c7111-f01f-4e29-b3a6-9b0ac81d9094"
},
"hide": true,
"refId": "C",
"scenarioId": "csv_metric_values",
"stringInput": "15,18,6,12,9,17,10,16,5,8,15,12,11,12,16"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$A+$B+$C",
"hide": true,
"refId": "D",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$A/$D",
"hide": false,
"refId": "E",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$B/$D",
"hide": false,
"refId": "F",
"type": "math"
},
{
"datasource": {
"name": "Expression",
"type": "__expr__",
"uid": "__expr__"
},
"expression": "$C/$D",
"hide": false,
"refId": "G",
"type": "math"
}
],
"title": "堆叠百分比统计 WebVitals CLS 指标示例",
"type": "timeseries"
}2. 多个堆叠百分比图完整示例#
通过创建多张针对不同指标的堆叠百分比图,我们就能对web-vitals各项指标有稳定、客观、可量化的监控,从而:
找到明确的优化目标:根据可视化图表快速定位用户体验相关的问题和痛点。
- 例如下图中的《LCP评分百分比》图表中的平均值(mean)数据中,38%的评分均为差(poor),说明相当多的用户在访问我们的网站时,遇到了最大元素(Largest Component)渲染较慢的问题,是一项值得优化的目标。
建立量化指标:将主观、不稳定的用户体验用客观、稳定的数据量化为清晰明了的图表。
切实改善用户体验: 帮助我们在优化前后,通过这些指标图表,客观准确地评估对用户体验的优化效果。
建立长效化的机制:通过长期观测、对比可视化图表,长期有效地感知用户体验的变化情况。
小结#
在本节中,我们学习了数据收集和可视化的实用工具:Prometheus 和 Grafana。
我们首先演示了接入Grafana的流程,并搭建了一个基于Express框架的Node.js服务器应用,利用prom-client的API,收集数据,并上报到Grafana。
其次,我们还学习了在Grafana页面中创建可视化图表的核心流程。
最后,我们学习了堆叠百分比评分图表的特点及其解决的痛点。